一、实验设计
1.1爬虫
为了自己建立数据集,首先需要获取图片,为了方便批量获取图片通过爬虫是最好的方法。我们选择爬取百度图片,搜索词为“男性/女性的脸部”,之后设置User—Agent,爬取图片,将图片分类保存至指定目录重命名,共爬取女性图5296张,男性图2022张。爬取过程中也设置了合理程序睡眠时间,错误输出保证用户友好性和维护的方便。
爬虫的代码在image_spider.py中,有注释,没有在这里展示,不然太长了。
# 开始获取
def __get_images(self,dir, word):
search = urllib.parse.quote(word)
# pn int 图片数
pn = self.__start_amount
while pn < self.__amount:
url = 'http://image.baidu.com/search/avatarjson?tn=resultjsonavatarnew&ie=utf-8&word=' + search + '&cg=girl&pn=' + str(
pn - 120) + '&rn=60&itg=0&z=0&fr=&width=&height=&lm=-1&ic=0&s=0&st=-1&gsm=1e0000001e'
print(url)
# 设置header防ban
try:
time.sleep(self.time_sleep)
req = urllib.request.Request(url=url, headers=self.headers)
page = urllib.request.urlopen(req)
rsp = page.read().decode('unicode_escape')
except UnicodeDecodeError as e:
print(e)
print('-----UnicodeDecodeErrorurl:', url)
except urllib.error.URLError as e:
print(e)
print("-----urlErrorurl:", url)
except socket.timeout as e:
print(e)
print("-----socket timout:", url)
else:
# 解析json
rsp_data = json.loads(rsp)
self.__save_image(rsp_data,dir, word)
# 读取下一页
print("下载下一页")
pn += 60
finally:
page.close()
print("下载任务结束")
return
def start(self,dir, word, spider_page_num=1, start_page=1):
"""
爬虫入口
:param word: 抓取的关键词
:param spider_page_num: 需要抓取数据页数 总抓取图片数量为 页数x60
:param start_page:起始页数
:return:
"""
self.__start_amount = (start_page - 1) * 60
self.__amount = spider_page_num * 60 + self.__start_amount
self.__get_images(dir,word)
1.2图片的处理
爬取的图片自然不能直接运用我们需要对其进行处理,在我们这一步工作中我们需要的人脸这一块来做训练因此我们先获取人脸。人脸获取我们用现有方法haarcascade_frontalface_alt.xml[5]这是个OpenCV训练好的正面人脸检测级联分类器,它对人脸的检测较为严格,光线,角度等都会影响它的工作,这么严格的检测可以帮助我们建立更好的数据集。此外此检测方法在灰度图下拥有更高的效率。所以这一步我们做的是将所有图片转化为灰度图,可通过cv2.cvtColour实现。将所有找到的脸再分别存到指定目录下,构成训练集。之后图像处理成128*128大小来为下一步训练做准备,标签只有两种男性和女性用0和1表示训练时看他们来自哪个文件夹即可。
处理的代码在handle_image.py中。
# 循环读取图片,添加到一个列表,每个图片为128 *128
def get_file(paths):
IMAGE_SIZE = 128
data = []
images_list = []
labels_list = []
counter = 0
if os.path.isfile ('data.pkl') :
with open ('data.pkl', 'rb') as fp :
data_list = pickle.load (fp)
return data_list[0], data_list[1], data_list[2]
for path in paths :
for dir_image in tqdm.tqdm(os.listdir(path)):
# print(dir_image)
if dir_image.endswith('.jpg'):
img = cv2.imread(os.path.join(path, dir_image))
resized_img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE))
colored_img = cv2.cvtColor(resized_img, cv2.COLOR_BGR2GRAY) #转为灰度图
data.append ([colored_img, counter])
counter += 1
1.3卷积神经网络
卷积神经网络是Yann LeCun,Wei Zhang等人在1987年-1989年提出的概念。其特殊结构有:
卷积层(Convolutional layer),卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
线性整流层(Rectified Linear Units layer, ReLU layer),这一层神经的活性化函数(Activation function)使用线性整流(Rectified Linear Units, ReLU)f(x)=max(0,x)f(x)=max(0,x) 。
池化层(Pooling layer),通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
全连接层( Fully-Connected layer), 把所有局部特征结合变成全局特征,用来计算最后每一类的得分。
同样我们按照这个结构构造卷积神经网络输入为128*128大小的面部图片,进行2层卷积filter大小32。池化采用MaxPooling每一层最后调用函数Dropout()来防止过度拟合,最后接全连接层softMax作为激活函数,且每次打印模型概况,实现上sklearn库、keras库提供了许多现有函数,因此不过太过于深入了解其内部数学原理,也能实现。
下图为各层概述:
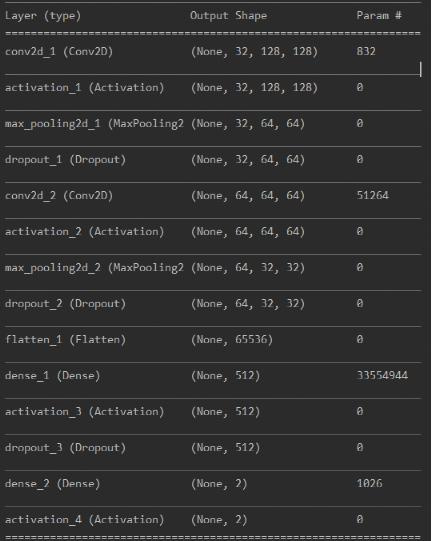
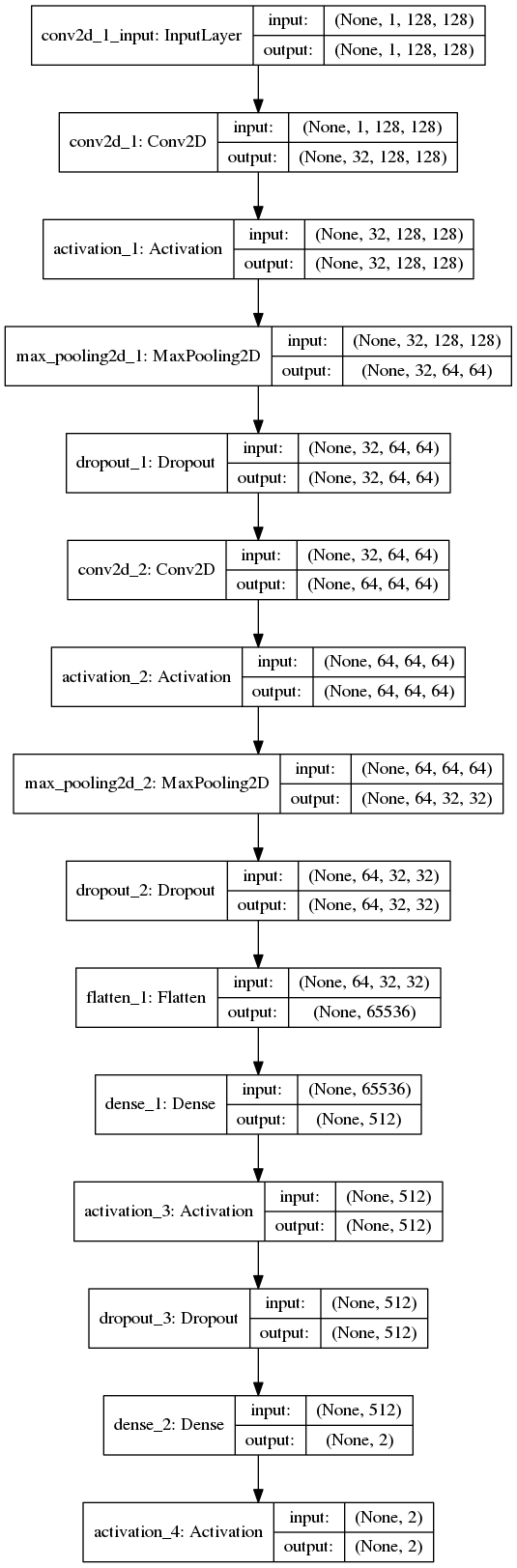
该部分的代码在image_train.py中,使用的是CNN构架实现的。
1.4 展示结果
首先是对图片进行识别,我们在训练过后,对准备好的测试样本进行测试,测试结果很好,识别成功率很高;我们还进行实时的图片处理工作,也就是用opencv库中的模块对系统的摄像头进行调用,实时采集人脸数据,进行处理识别。
二、实验环境
实验数据由我们自行收集处理,来源为百度图片和Wiki的数据集。
PS:数据集由于文件过大并没有附在文件中,如有需要请自行爬取。
程序编写我们用Python实验,作为编写人工智能的主流语言其有方便、有较多现有资源的特点。Python为3.6版本。除默认库外我们用了urllib、re、socket用于爬虫。cv2、sklearn、keras用于深度学习。matplotlib.pyplot用于画图。
在Linux和Windows10系统均试验过,且成功。
三、运行结果、实验结论
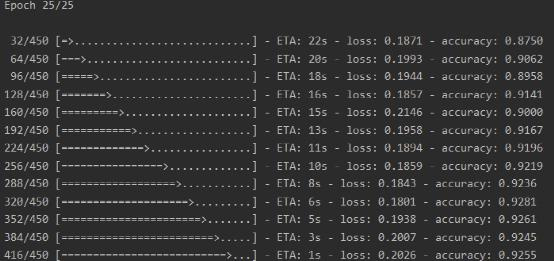
经过25组450次的训练最终能在测试集上达到接近95%的准确率。样本输出如下图所示。

实验结论:本系统能完成对一人脸图判断其男女,且具有较高的准确率。
参考文献:
[1] Vera-Rodriguez, R., Blazquez, M., Morales, A., Gonzalez-Sosa, E., Neves, J.C. and Proenca, H., 2019. FaceGenderID: Exploiting Gender Information in DCNNs Face Recognition Systems. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (pp. 0-0).
[2] Ranjan, R., Patel, V. M., & Chellappa, R. (2017). Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(1), 121-135.
[3] 方晟. 基于人脸特征的性别判断和年龄估计方法研究[D].浙江大学,2015.
[4] 刘尚旺,刘承伟,张爱丽.基于深度可分卷积神经网络的实时人脸表情和性别识别[J/OL].计算机应用:1-8[2019-12-06].
[5] https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_alt.xml
本文项目下载:
源代码.zip (98.7 KB)
- 通过
- 未通过
0 投票者