
今天学习的内容是让大家简单的了解下病毒静态分析技术,若有不当之处希望伙伴们可以指出,让我们共同完善,共同进步(✿◡‿◡)
![]()
开始进入正文:
(✿◡‿◡)咳咳梦幻开讲了,请伙伴们准备好瓜子、可乐以及其它小零食
原理:程序静态分析(Program Static Analysis)是指在不运行代码的方式下,通过词法分析、语法分析、控制流、数据流分析等技术对程序代码进行扫描,验证代码是否满足规范性、安全性、可靠性、可维护性等指标的一种代码分析技术。可利用该技术来验证软件是否为病毒,一般重以下几个方面进行分析:
字符串查杀
在程序未运行的情况下,使用一些工具,提取程序字符串,查看是否有可疑信息,来判断是否为病毒,原理与解析如下:
- 定义:字符串或串(String)是由数字、字母、下划线组成的一串字符,主要用于编程,概念说明、函数解释等,
补充知识:字符串在存储上类似字符数组,所以它每一位的单个元素都是可以提取的 - 常用于:输出信息、URL地址、文件名称、路径信息等等。
因计算机只能识别0和1两种数字,为了使用输入指定的字符串,常使用编码技术来解决这一问题
定义:编码是信息从一种形式或格式转换为另一种形式的过程也称为计算机编程语言的代码简称编码。用预先规定的方法将文字、数字或其它对象编成数码,或将信息、数据转换成规定的电脉冲信号。编码在电子计算机、电视、遥控和通讯等方面广泛使用。编码是信息从一种形式或格式转换为另一种形式的过程。解码,是编码的逆过程。
常见编码技术
ASCII编码:是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
Unicode编码:是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
GB 2312编码:适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312。
GBK编码:GBK编码标准兼容GB2312,共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。
如何从计算机的二进制编码中,提取出字符串,可以使用以下工具
Strings
官网:https://docs.microsoft.com/zh-cn/sysinternals/downloads/strings
功能:在对象文件或二进制文件中查找可打印的字符串
缺陷:但是它将忽略上下文格式。搜索出的可能是:内存地址、CPU指令序列、一段数据等等
限制:它只搜索三个或以上连续的ASCII(2个0结尾)或Unicode(4个0结尾)字符,并以终结符结尾的可打印字符串。
针对:计算机病毒可利用该搜索限制,导致Strings搜索不到有用字符串(例如:将所有字符变成两个字符,在进行拼接)
技巧:搜索时修改文件后缀名,避免运行
案例:
- SDL Passolo
官网:https://www.sdltrados.cn/cn/products/passolo/
功能:软件本地化工具,当然也可以搜索字符串
缺陷:程序体积大 - Resource Hacker
官网:https://www.sdltrados.cn/cn/products/passolo/ - Lingobit Localizer
官网:http://www.lingobit.com/zh/index.html - Resource Tuner
官网:http://www.restuner.com/ - Restorator
官网:https://www.bome.com/products/restorator - Sisulizer
官网:https://www.sisulizer.com/ - 一般搜索到url或其它IP地址就要小心了,很有可能就是病毒,做好防护在访问验证,避免网页挂马。
PE查杀
由于大多数感染型病毒都是感染的PE文件,因为这样才可以在PE文件运行的同时运行自身的病毒代码。从而继续感染其他的正常文件,以达到传播的自身的目的。所以从杀毒角度讲,应该先判断一个文件是否为PE结构,再去进一步决定应该使用何种方法对文件进行扫描处理。那么,如何判断一个文件是否为PE结构呢,先从pe的概念开始入手:
- PE概念:PE( Portable Execute)文件是Windows下可执行文件的总称,常见的有 DLL,EXE,OCX,SYS 等
- 适用范围:Windows可执行程序和动态链接库
- 包含信息:Windows如何将文件从硬盘装载到内存中执行所需的必要信息
事实上,一个文件是否是 PE 文件与其扩展名无关,PE文件可以是任何扩展名。那 Windows 是怎么区分可执行文件和非可执行文件的呢?我们调用 LoadLibrary 传递了一个文件名,系统是如何判断这个文件是一个合法的动态库呢?这就涉及到PE文件结构了。 - PE结构
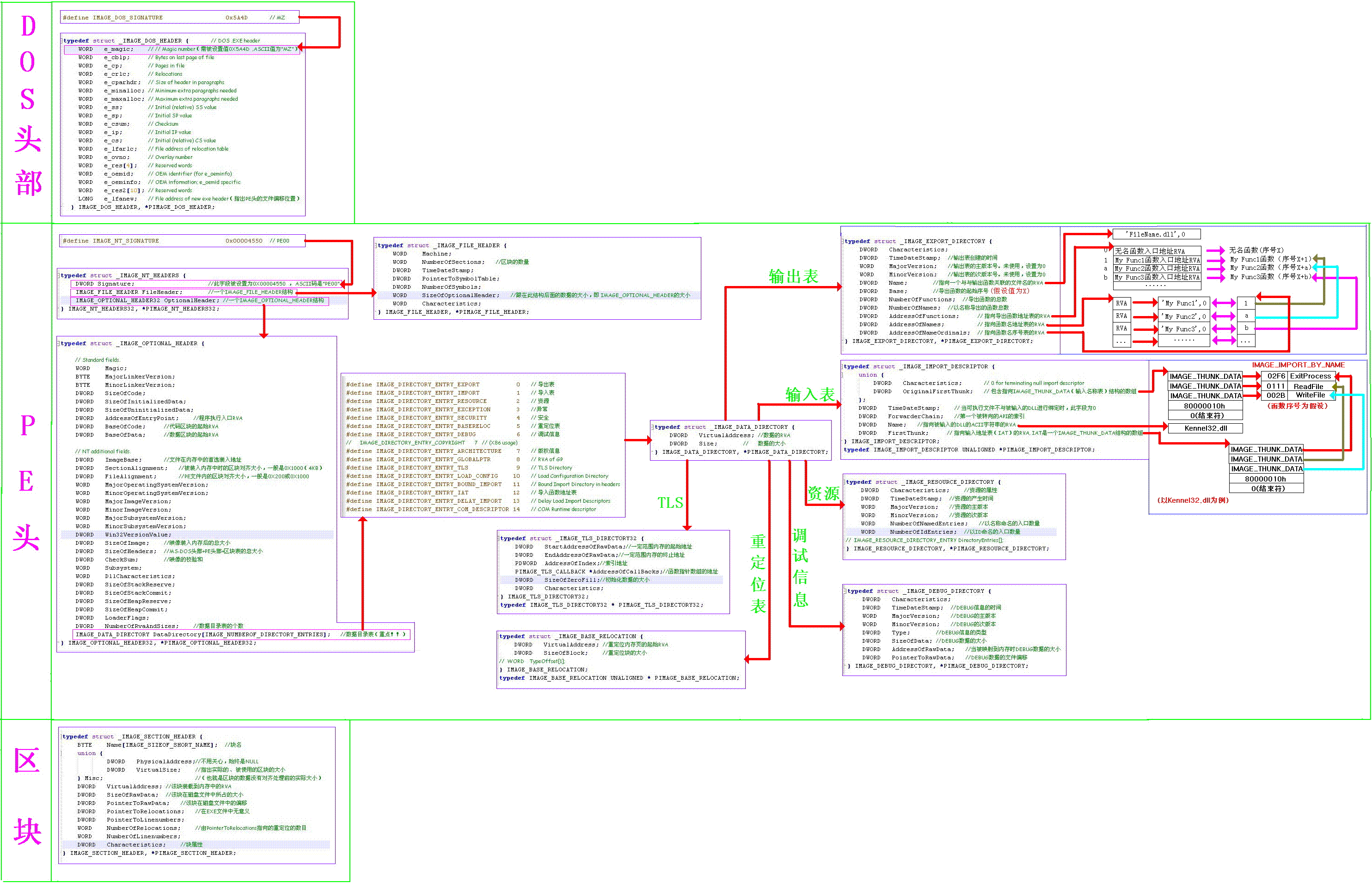
DOS头:
DOS头中声明用的寄存器(可以看到e_ss、e_sp、e_ip、e_cs还是16位的寄存器),所以在32位/64为系统中用到的只有两个:
- e_magic:判断一个文件是不是PE文件,使用MZ标记;//(WORD 2字节变量)
- e_lfanew:相对于文件首的偏移量,用于找到PE头;//(DWORD 4字节变量)
struct _IMAGE_DOS_HEADER
typedef struct _IMAGE_DOS_HEADER {
WORD e_magic; //※Magic DOS signature MZ(4Dh 5Ah):MZ标记:用于标记是否是可执行文件
WORD e_cblp; //文件最后一页的字节数
WORD e_cp; //文件中的页面
WORD e_crlc; //重新安置
WORD e_cparhdr; //段落标题大小
WORD e_minalloc; //最少的额外段落需求
WORD e_maxalloc; //最大的额外段落需求
WORD e_ss; //初始(相对)SS值
WORD e_sp; //初始SP值
WORD e_csum; //校验和
WORD e_ip; //初始IP值
WORD e_cs; //初始(相对)CSS值
WORD e_lfarlc; //重定位表的文件地址
WORD e_ovno; //叠加数
WORD e_res[4]; //保留字
WORD e_oemid; //OEM标识符(用于e_oeminfo)
WORD e_oeminfo; //OEM信息;特定于e_oemid
WORD e_res2[10]; //保留字
DWORD e_lfanew; //※Offset to start of PE header:定位PE文件,PE头相对于文件的偏移量
}IMAGE_DOS_HEADER, * PIMAGE_DOS_HEADER;
PE文件头:
PE头分为标准PE头和可选PE头,其同为NT结构的成员,记录可执行代码信息
- 包含:程序的类型,exe可执行程序、dll动态链接库程序
- 作用:Windows基于PE文件头来将可执行程序和所依赖的动态链接库映射到内存中
- 标准PE头:
struct IMAGE_FILE_HEADER
typedef struct _IMAGE_FILE_HEADER
{
WORD Machine; //※程序执行的CPU平台:0X0:任何平台,0X14C:intel i386及后续处理器
WORD NumberOfSections; //※PE文件中区块数量
ULONG TimeDateStamp; //时间戳:连接器产生此文件的时间距1969/12/31-16:00P:00的总秒数
ULONG PointerToSymbolTable;//COFF符号表格的偏移位置。此字段只对COFF除错信息有用
ULONG NumberOfSymbols; //COFF符号表格中的符号个数。该值和上一个值在release版本的程序里为0
WORD SizeOfOptionalHeader;//IMAGE_OPTIONAL_HEADER结构的大小(字节数):32位默认E0H,64位默认F0H(可修改)
WORD Characteristics; //※描述文件属性(单属性(只有1bit为1):#define IMAGE_FILE_DLL 0x2000 //File is a DLL;组合属性(多个bit为1,单属性或运算):0X010F 可执行文件)
} IMAGE_FILE_HEADER; //*PIMAGE_FILE_HEADER;
- 可选PE头:
struct IMAGE_OPTIONAL_HEADER
typedef struct _IMAGE_OPTIONAL_HEADER
{
WORD Magic; //※ 说明文件类型:10B 32位、20B 64位
UCHAR MajorLinkerVersion; //链接程序的主版本号
UCHAR MinorLinkerVersion; //链接程序的副版本号
ULONG SizeOfCode; //所有代码段的总和大小,注意:必须是FileAlignment的整数倍
ULONG SizeOfInitializedData; //已经初始化数据的大小,注意:必须是FileAlignment的整数倍
ULONG SizeOfUninitializedData; //未经初始化数据的大小,注意:必须是FileAlignment的整数倍
ULONG AddressOfEntryPoint; //※程序入口地址OEP,这是一个RVA(Relative Virtual Address),通常会落在.textsection,此字段对于DLLs/EXEs都适用。
ULONG BaseOfCode; //代码段起始地址(代码基址),(代码的开始和程序无必然联系)
ULONG BaseOfData; //数据段起始地址(数据基址)
ULONG ImageBase; //※内存镜像基址(默认装入起始地址),默认为4000H
ULONG SectionAlignment; //※内存中的区块的对齐大小:一旦映像到内存中,每一个section保证从一个「此值之倍数」的虚拟地址开始
ULONG FileAlignment; //※文件中的区块的对齐大小:最初是200H,现在是1000H
WORD MajorOperatingSystemVersion; //所需操作系统主版本号
WORD MinorOperatingSystemVersion; //所需操作系统副版本号
WORD MajorImageVersion; //自定义主版本号,使用连接器的参数设置,eg:LINK /VERSION:2.0 myobj.obj
WORD MinorImageVersion; //自定义副版本号,使用连接器的参数设置
WORD MajorSubsystemVersion; //所需子系统主版本号,典型数值4.0(Windows 4.0/即Windows 95)
WORD MinorSubsystemVersion; //所需子系统副版本号
ULONG Win32VersionValue; //※莫须有字段,不被病毒利用的话一般为0
ULONG SizeOfImage; //※PE文件在内存中映像总大小,sizeof(ImageBuffer),SectionAlignment的倍数
ULONG SizeOfHeaders; //※DOS头(64B)+PE标记(4B)+标准PE头(20B)+可选PE头+节表的总大小,按照文件对齐(FileAlignment的倍数)
ULONG CheckSum; //※PE文件CRC校验和,判断文件是否被修改
WORD Subsystem; //用户界面使用的子系统类型
WORD DllCharacteristics; //DllMain()函数何时被调用,默认为 0
ULONG SizeOfStackReserve; //默认线程初始化线程栈的保留大小
ULONG SizeOfStackCommit; //初始化时实际提交的线程栈大小
ULONG SizeOfHeapReserve; //默认保留给初始化的线程栈的虚拟内存大小
ULONG SizeOfHeapCommit; //初始化时实际提交的堆大小
ULONG LoaderFlags; //与调试有关,默认为 0
ULONG NumberOfRvaAndSizes; //目录项数目:总为0X00000010H(16),这个字段自Windows NT 发布以来一直是16
IMAGE_DATA_DIRECTORY DataDirectory[16]; //定义IMAGE_NUMBEROF_DIRECTORY_ENTRIES 16
} IMAGE_OPTIONAL_HEADER, *PIMAGE_OPTIONAL_HEADER;
PE节表:
PE文件中所有节的属性都被定义在节表中,节表由一系列的IMAGE_SECTION_HEADER结构排列而成,每个结构用来描述一个节,结构的排列顺序和它们描述的节在文件中的排列顺序是一致的。全部有效结构的最后以一个空的IMAGE_SECTION_HEADER结构作为结束,所以节表中总的IMAGE_SECTION_HEADER结构数量等于节的数量加一。节表总是被存放在紧接在PE文件头的地方。
另外,节表中 IMAGE_SECTION_HEADER 结构的总数总是由PE文件头 IMAGE_NT_HEADERS 结构中的 FileHeader.NumberOfSections 字段来指定的。
struct IMAGE_SECTION_HEADER
typedef struct _IMAGE_SECTION_HEADER
{
BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; //区块名。这是一个由8位的ASCII 码名,用来定义区块的名称。多数区块名都习惯性以一个“.”作为开头(例如:.text),这个“.” 实际上是不是必须的。值得我们注意的是,如果区块名超过 8 个字节,则没有最后的终止标志“NULL” 字节。并且前边带有一个“$” 的区块名字会从连接器那里得到特殊的待遇,前边带有“$” 的相同名字的区块在载入时候将会被合并,在合并之后的区块中,他们是按照“$” 后边的字符的字母顺序进行合并的。
另外每个区块的名称都是唯一的,不能有同名的两个区块。但事实上节的名称不代表任何含义,他的存在仅仅是为了正规统一编程的时候方便程序员查看方便而设置的一个标记而已。所以将包含代码的区块命名为“.Data” 或者说将包含数据的区块命名为“.Code” 都是合法的。当我们要从PE 文件中读取需要的区块时候,不能以区块的名称作为定位的标准和依据,正确的方法是按照 IMAGE_OPTIONAL_HEADER32 结构中的数据目录字段结合进行定位。
union {
DWORD PhysicalAddress; //物理地址
DWORD VirtualSize; //该区块表对应的区块的大小,这是区块的数据在没有进行对齐处理前的实际大小。
} Misc;
DWORD VirtualAddress; //该区块装载到内存中的RVA 地址。这个地址是按照内存页来对齐的,因此它的数值总是 SectionAlignment 的值的整数倍。在Microsoft 工具中,第一个快的默认 RVA 总为1000h。在OBJ 中,该字段没有意义地,并被设为0
DWORD SizeOfRawData; //该区块在磁盘中所占的大小。在可执行文件中,该字段是已经被FileAlignment 处理过的长度
DWORD PointerToRawData; //该区块在磁盘中的偏移。这个数值是从文件头开始算起的偏移量
DWORD PointerToRelocations; //在EXE文件中没有意义,在OBJ 文件中,表示本区块重定位信息的偏移值
DWORD PointerToLinenumbers; //行号表在文件中的偏移值,文件的调试信息
WORD NumberOfRelocations; //在EXE文件中也没有意义,在OBJ 文件中,是本区块在重定位表中的重定位数目
WORD NumberOfLinenumbers; //该区块在行号表中的行号数目
DWORD Characteristics; //该区块的属性。该字段是按位来指出区块的属性(如代码/数据/可读/可写等)的标志
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
PE节:
每个节实际上是一个容器,可以包含 代码、数据 等等,每个节可以有独立的内存权限,比如代码节默认有读/执行权限,节的名字和数量可以自己定义
- 常见的节:
.text:包含了CPU的执行指令、所有其它分节存储数据、支持性的信息。一般来说,它是唯一可以执行的分节,也是唯一包含代码的节,其中的数据是可读、可执行的,并且利用CPU指令动态生成技术,可让数据具有可读、可写、可执行功能。
.rdata:包含的数据只具有只读功能,通常用来包含导入导出函数信息,还可以存储程序所使用的其它只读数据,比如导入的动态链接库、导入的函数信息等。
.date:程序所用的全局变量信息保存在这里,它的数据是可读、可写的。
.rsrc:该字节包含由可执行文件所使用的资源信息,但这些内容并不能执行的,比如图标、图片、菜单项和字符串,也可以用来存储其它程序,危害的是也可被用来存储病毒,在程序运行的时候将这些病毒加载到内存当中 - 常用的PE分析工具
PEview(roguekillerpe):https://www.adlice.com/download/roguekillerpe/
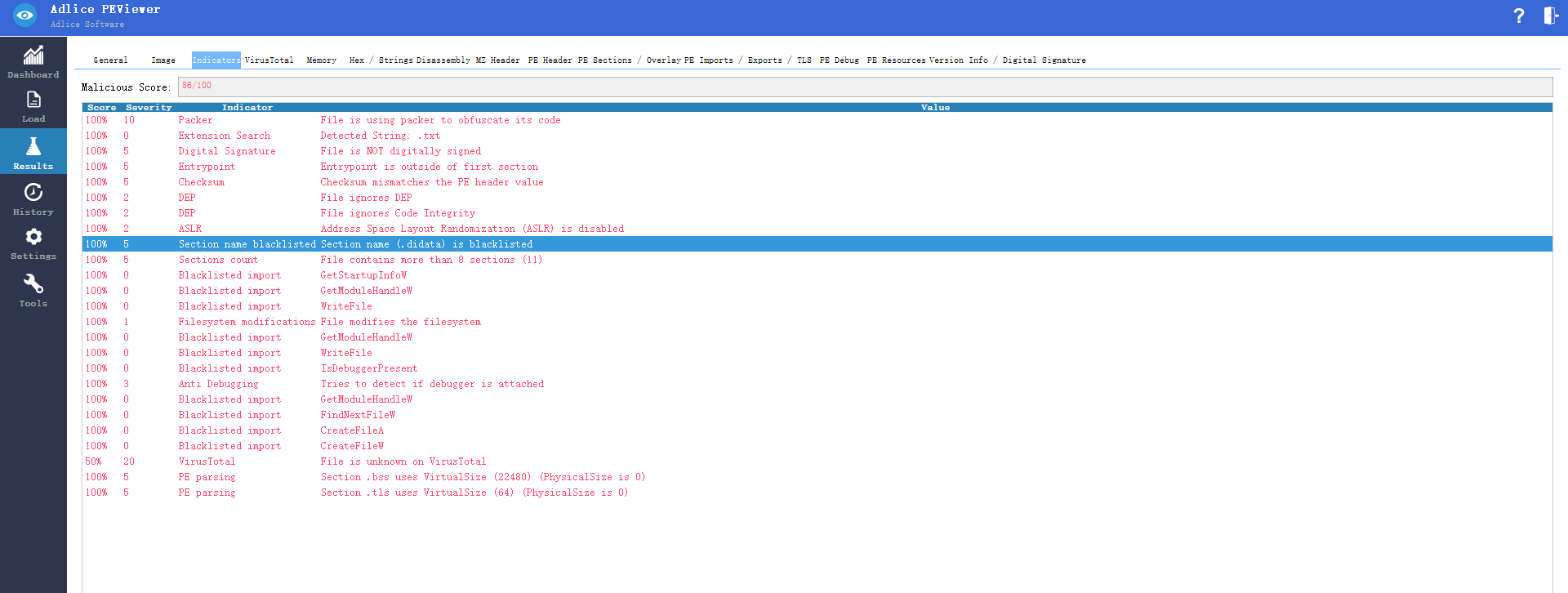
StudyPE:https://www.chinapyg.com/forum.php?mod=viewthread&tid=137051&highlight=study%2Bpe
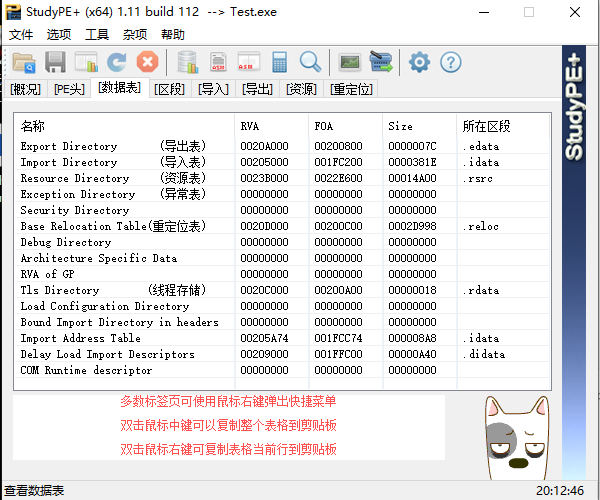
PPEE:https://mzrst.com/
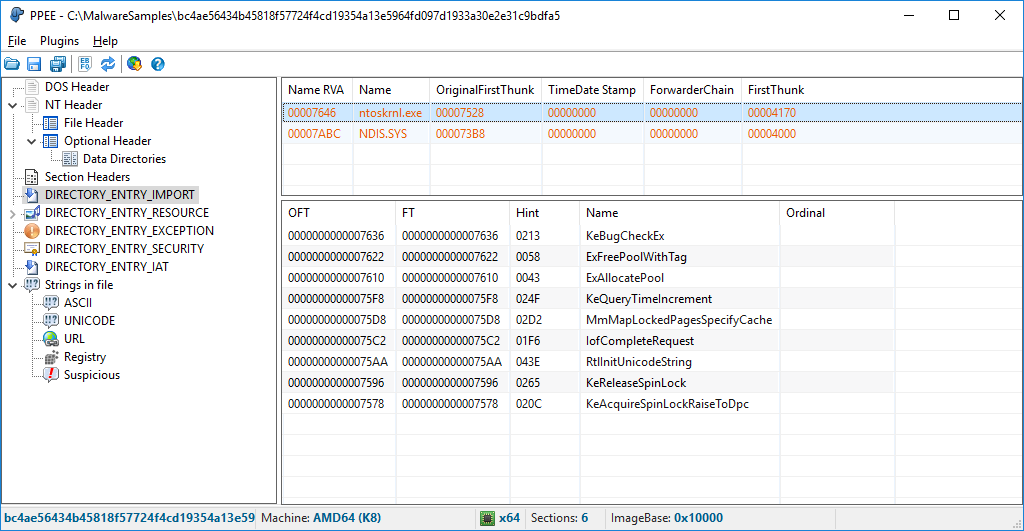
CFF Explorer:https://ntcore.com/?page_id=388
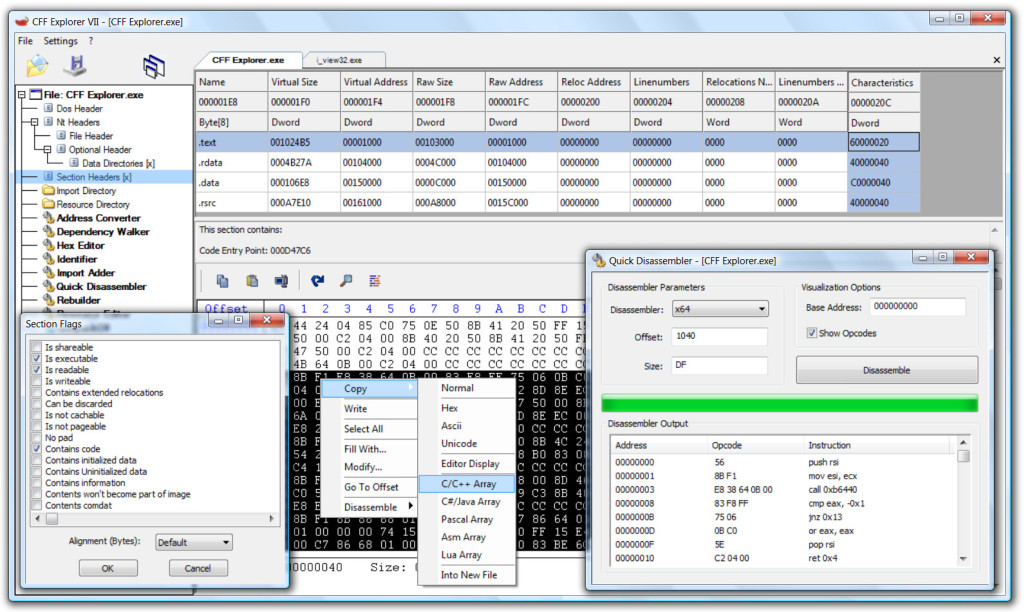
PE Explorer:http://www.heaventools.com/overview.htm
查杀技巧:
- 判断PE 文件中程序入口点是否异常
很多病毒在感染了PE文件后,通常都会向PE文件中添加一部分代码, 然后更改P E 头中的AddressOfEntryPoint,将他指向的地址定位到病毒插入的代码处,这样每当这个文件运行时,病毒代码都会最先得到运行。
一般情况,很多病毒都将插入到PE文件中的代码放到PE文件的后面,然后在代码尾部放置一条语句再跳回到原来PE文件真正入口点处。使得用户在毫无察觉的情况下执行病毒代码。杀毒软件可以根据PE文件入口点是否异常来判断文件是否有被病毒感染的嫌疑。通常入口点所指的相对虚拟地址比较靠前,不会在靠近文件末尾处,或者指向最后一个节后的内容,如果一个PE文件的入口点的指向不是这样,那么就说明这个文件有被病毒感染的嫌疑。当然,这种主观的判断不一定准确,但是可以算是一种判断的依据。上期我们提到的启发式扫描就会用到这样的特征来帮助判断未知病毒。
有些病毒为了防止反病毒软件的这种探测,也想出了很多不修改入口点改变程序流程的方法。例如,改变原入口点程序的代码,再跳转到病毒体。 - 根据PE 结构取特征码
特征码的提取是将文件划分为不同的部分,然后从每部分中提取一定长度的内容作为特征码。这样提取特征码的方法存在着一个问题就是很多病毒的特征码有类似的部分,例如我们讨论的PE结构,很多PE文件开头部分有很大一部分是相同的,所以按照等分划分文件的方法来提取特征码是不理想的。这时我们考虑到了利用PE结构,从每个节中提取一定的内容作为特征码,或者以各种关键点为参照,在附近找特征码。这样一来,可以大大避免了上面所提到的等分划分文件提取特征码方法的弊端,增强了不同病毒间特征码的差异性。例如本次对于CIH 病毒的检测,就检查了PE Header 附近和入口点附近的特征。
案例:
- CIH病毒的识别
取3 个特征:
首先是在PE Header前一个字节如果非0,就有可能感染了,CIH 自己也利用了这个来判断。
但是这个特征是不一定可靠的,没有感染CIH病毒的程序这个地方也可能因为各种原因变成非0,所以还加了两条代码特征。
CIH会改变代码入口,指向自己,根据这个,我们取了入口点偏移特征,将sidt动作和后面挂文件系统钩子两个动作作为了特征,这样就比较可靠了。
当然,这3个特征都集中在病毒头部,如果要更可靠,避免家族内的误报,还可以增加一些病毒体后面的代码
链接库与函数
在计算机病毒分析中链接库与函数可以给病毒分析带来很多有用的信息,那它们又是如何被计算机病毒盯上的呢?怀着这个疑问,进行进一步的学习:
盯上原因:病毒利用PE结构中的导入表将计算机病毒需要的链接库、函数等含有恶意内容的东西导入到计算机内存里面,并调用动态链接库中的函数(通过链接库将计算机病毒代码与动态链接库连接在一起)进行准备工作
- 引入问题:链接是什么都有什么链接方法
链接所解决的问题即是将我们自己写的代码和别人写的库集成在一起。 - 静态链接:是Windows平台链接代码库最不常用的方法,但在UNIX和Linux程序中是比较常见的。
- 特点:在生成可执行文件的时候(链接时间),把所有需要的函数的二进制代码都包含到可执行文件中去。因此,链接器需要知道参与链接的目标文件需要哪些函数,同时也要知道每个目标文件都能提供什么函数,这样链接器才能知道是不是每个目标文件所需要的函数都能正确地链接。
如果某个目标文件需要的函数在参与链接的目标文件中找不到的话,链接器就报错了。
目标文件中有两个重要的接口来提供这些信息:一个是符号表,另外一个是重定位表。
当一个库被静态链接到可执行程序时,所有这个库中的代码都会复制到可执行程序中去。 - 优点:在程序发布的时候就不需要的依赖库,也就是不再需要带着库一块发布,程序可以独立执行。
- 缺点:但在PE文件头中没有链接库的信息,这种方法会导致可执行程序体积变大,占用更多的内存空间;如果静态库有更新的话,所有可执行文件都得重新链接才能用上新的静态库。通常计算机病毒为减小病毒体积一般不使用这种链接方法。
- 链接时间:在生成可执行文件的时候(编译过程中进行的链接)
- 动态链接:动态链接时最常见的,对于恶意代码分析师也应该时最关注的,动态链接信息写在导入表中,当代码库被动态链接时,宿主操作系统会在程序被装载时搜索所需要的代码库,如果程序调用了被链接的库函数,这个函数会在代码库中执行
- 特点:在编译的时候不直接拷贝可执行代码,而是通过记录一系列符号和参数,在程序运行或加载时将这些信息传递给操作系统,操作系统负责将需要的动态库加载到内存中,然后程序在运行到指定的代码时,去共享执行内存中已经加载的动态库可执行代码,最终达到运行时连接的目的。
- 优点:多个程序可以共享同一段代码,而不需要在磁盘上存储多个拷贝。
- 缺点:由于是运行时加载,可能会影响程序的前期执行性能。
- 链接时间:在程序运行或加载时
- 运行时链接:当应用程序调用LoadLibrary 或 LoadLibraryEx 函数时,系统就会尝试按载入时动态链接搜寻次序(参见载入时动态链接)定位DLL。如果找到,系统就把DLL模块映射到进程的虚地址空间中,并增加引用计数。如果调用LoadLibrary或LoadLibraryEx 时指定的DLL其代码已经映射到调用进程的虚地址空间,函数就会仅返回DLL的句柄并增加DLL引用计数。注意:两个具有相同文件名及扩展名但不在同一目录的DLL被认为不是同一个DLL。
备注:虽然运行时链接在合法程序中并不流行,但是恶意代码中是常用的,特别是当恶意代码被加壳或混淆的时候。因为加壳或混淆会破坏计算机病毒的导入表,没有导入表Windows系统不会帮助病毒完成链接工作,所以需要在运行的时候利用运行时链接这种方法,将所需要的链接库和函数装载到内存空间中。
- 特点:需要的适合才进行链接
- 优点:使用运行时链接的可执行程序,只有当需要使用函数时,才链接到库,而并不是像动态链接模式一样在程序启动时就会链接
- 缺点:需要使用相关函数才可以调用
- 链接时间:遇到调用函数时
- 基于链接的分析:
PE文件头列出了计算机病毒代码所需的所有动态链接库和函数
动态链接库和函数名字可以用来分析计算机病毒的功能
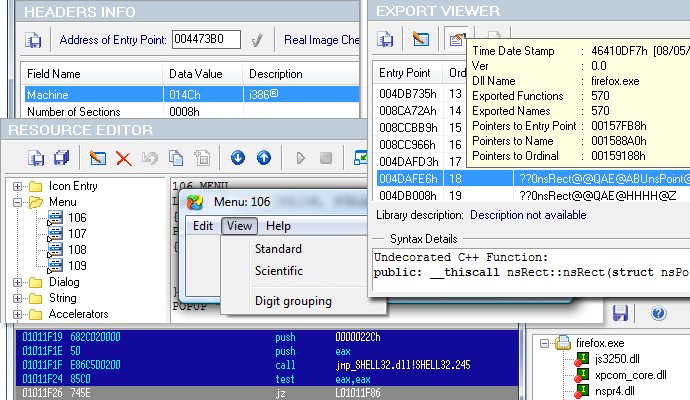
常用的动态链接库的信息: - 常用的分析工具:
Dependency Walker:包含在Visual Studio的一些版本与其它微软开发包中,支持列出可执行文件的动态链接函数 - 病毒中常见的函数:
- LoadLibrary:将动态链接库动态的从硬盘装载到计算机病毒的内存空间
- GetProcAddress:在动态链接库中找到对应函数的地址
- URLDownloadToFile():会从Internet上下载一个文件
- 导入函数
PE文件头中也包含了可执行文件使用的特定函数相关信息,因为在导入函数只能看到这个函数的名字,为了了解函数的参数信息、功能信息以及使用方法,可以在微软的MSDN中找到这些信息,当然了使用搜索引擎也是可以的。 - 导出函数
与导入函数类似,DLL和EXE的导出函数,是用来与其它程序和代码进行交互时所使用的。 - 通常,一个DLL会实现一个或多个功能函数,然后将它们导出,是的别的程序可以导入并使用这些函数。
PE文件中也包含了一个文件中导出了哪些函数信息
辅助查杀
常用杀毒软件、恶意软件查杀平台、恶意软件分析平台等进行辅助查杀,它们具有如下优势:
- 拥有病毒特征库:一个数据库,它里面记录着已知病毒的种种“相貌特征”,根据这些专属特征,可鉴定软件是否为病毒,主要针对已知病毒。
病毒针对:计算机病毒的编写者可以很容易的修改自己的代码,从而改变这些病毒的各种特征,常通过如下技术来躲避杀毒软件的检测
多态技术:语义不变,语法混淆,增加逆向分析难度。
变形技术:功能不变,语义混淆,增加逆向分析难度。
单向执行技术:未解密数字猜想、哈希值,增加逆向分析难度。
垃圾指令:使用大量对分析时无用的指令,增加逆向分析难度。
- 拥有启发式规则:因有的病毒特征在特征库没有,杀毒软件未查杀这些未知病毒,就根据已知的病毒分析经验总结出一些规则,来鉴定软件是否为病毒,主要针对未知病毒。
病毒针对:开发新型病毒,不使用也被杀毒软件知道的特征与行为已避开杀毒软件检测
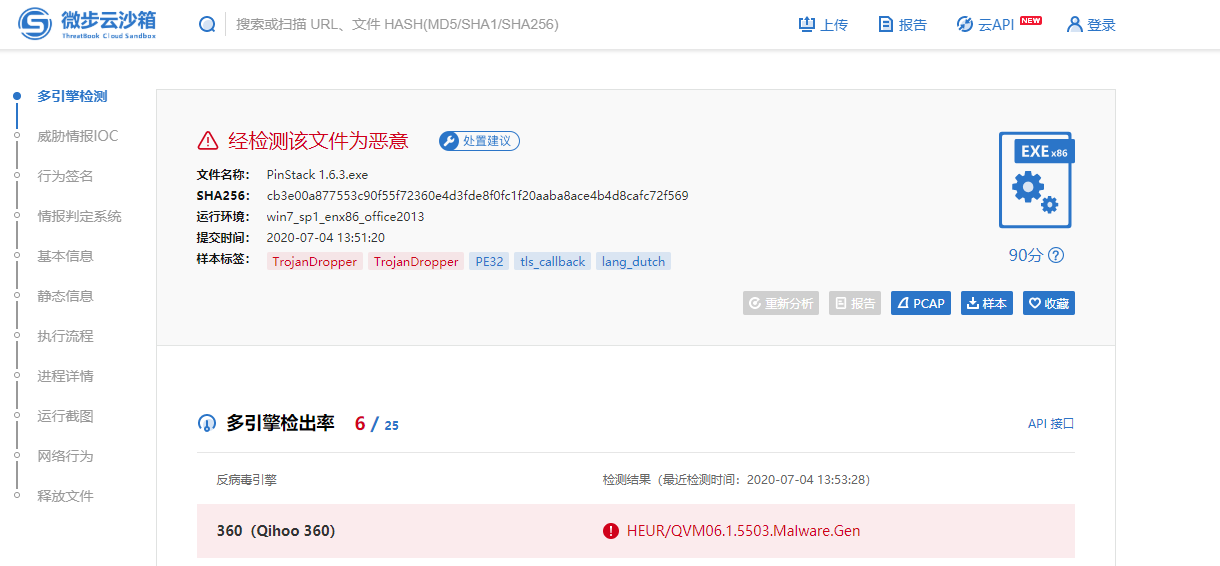
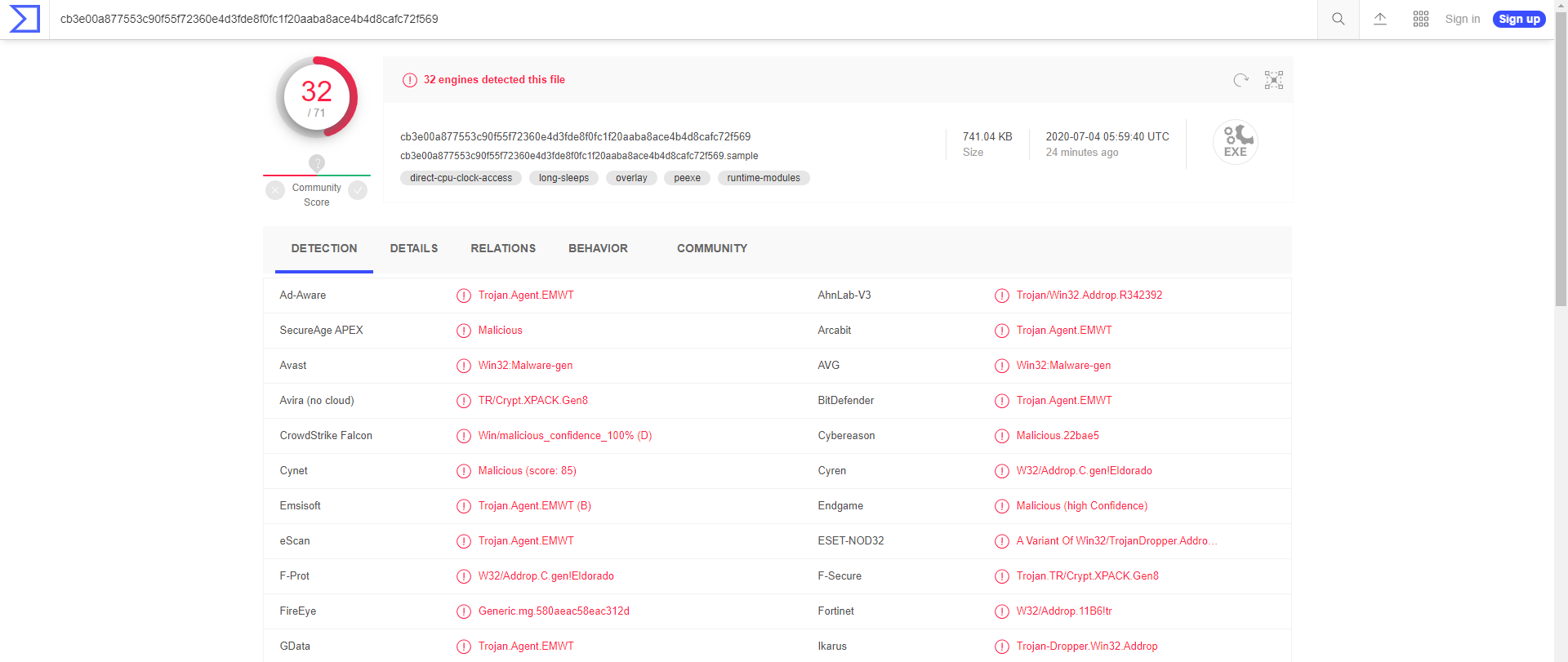
当本地无杀毒软件,流量不是很多等条件存在限制的情况下,可通过进算文件Hash值,到一些网站利用Hash值进行查杀,原理以及常见的查询平台如下:
- 原理:哈希值是一种独特的算法(哈希函数)计算出文件的唯一标识符,不同文件都不相同,影响因素可以是文件大小,内容,创建日期等……计算出哈希值,利用这些特性可以了解文件没有损坏或被修改也可用来在查询平台查询分析结果。
- 计算工具:
Hasher Pro:http://www.den4b.com/
HashOnClick : https://www.2brightsparks.com
Hash Generator Pro:http://insili.co.uk/
MD5 File Hasher Pro:http://www.digital-tronic.com/md5-file-hasher/
Advanced Hash Calculator:http://www.filesweb.com/ - 查询平台:
微布云沙箱:https://s.threatbook.cn/
Virus Toal:https://www.virustotal.com/gui/home/search
道高一尺魔高一丈
病毒未避免被静态分析技术分析出来,常使用加壳、混淆技术,来躲避静态分析
- 目的:躲避杀毒软件的检测并增加病毒分析工作的难度
- 混淆:隐藏计算机病毒程序的信息
常用工具:
爱加密:https://www.ijiami.cn/
DotFuscator:https://www.preemptive.com/
DashO Pro:https://www.preemptive.com/
ProGuard:https://www.guardsquare.com/en/proguard
Virbox Protector:https://shell.virbox.com/
Code Virtualizer:https://www.oreans.com/
Skater .NET obfuscator:http://www.rustemsoft.com/ - 加壳:压缩计算机病毒文件的大小,并使用加密技术保护病毒的核心代码
常用工具:
爱加密:https://www.ijiami.cn/
360加固保:https://jiagu.360.cn/
UPXShell:http://upxshell.sourceforge.net/download.html
DRMsoft EncryptEXE:http://www.drmsoft.com/
Vmproject:https://vmpsoft.com/
针对病毒的防护策略,常通过脱壳、反混淆技术来进行协助分析
- 脱壳:脱壳即去掉软件所加的壳,软件脱壳有手动脱和自动脱壳之分
常见工具:
QuickUnpack:http://qunpack.ahteam.org/?p=458#more-458
frida-unpack:https://github.com/WeiEast/frida-unpack
de4dot:https://github.com/0xd4d/de4dot
drizzleDumper:https://github.com/DrizzleRisk/drizzleDumper
de4js:https://github.com/lelinhtinh/de4js
wxappUnpacker:https://github.com/gzh4213/wxappUnpacker
Android_unpacker:https://github.com/CheckPointSW/android_unpacker
unpacker:https://github.com/malwaremusings/unpacker - 反混淆:让代码还原到美观,高可读性的状态
常用工具:
simplify:https://github.com/CalebFenton/simplify
de4dot:https://github.com/0xd4d/de4dot
flare-floss:https://github.com/fireeye/flare-floss
Tigress_protection:https://github.com/JonathanSalwan/Tigress_protection
VTIL-Core:https://github.com/vtil-project/VTIL-Core
dex-oracle:https://github.com/CalebFenton/dex-oracle
malware-jail:https://github.com/HynekPetrak/malware-jail
de4js:https://github.com/lelinhtinh/de4js
dnpatch:https://github.com/ioncodes/dnpatch
etacsufbo:https://github.com/ChiChou/etacsufbo
samsung-firmware-magic:https://github.com/chrivers/samsung-firmware-magic
JRemapper:https://github.com/Col-E/JRemapper
到此告一段落,期待下次相见,再续前缘(✿◡‿◡)