kAFL
0x00 贡献点:
- 系统无关
- 基于硬件的状态反馈
- 可扩展和模块化
- 开源
0x01 在未读文章之前心里的几个问题:
-
怎么做到的系统无关?在给kvm和qemu都下patch的情况下?难道是linux kernel作为直接作为host VMM吗?再通过qemu进行系统无关的测试?
-
什么是agent?
-
fuzzing kernel的时候输入是什么?
-
hypercall是怎么设计的?
-
fuzzer kernel 发生系统级别的crash怎么办?或者说怎么定义在kernel的crash(像二进制那样)
-
整个系统虚拟化的构建是怎么样的?
-
如何利用intel PT?
-
关于qemu-pt相关patch的实践?
-
最后也是构造了AFL里面的bitmap,那么如何通过intel PT的数据来构造的?
0x02 通过阅读得到的答案
-
Agent 是什么?
全称User Mode Agent,它运行在虚拟化的系统中,用于通过hypercall 同步fuzzing逻辑的输入和输出,比如你想测试一个文件系统,那么输入就是文件映像,通过挂载文件映像,来实现对内核的输入。
实际上在实践中,还存在一个loader组件,用于接收所有通过hypercall传输的二进制,这些二进制就代表 user mode agent,这些二进制通过loader来执行。这样策略是得可以重用一个VM的快照,通过传输不同的二进制。
这里我其实还有一个问题,这里面有两个agent,一个agent 负责运行用来处理payload的另一个agent。那么第一个loader agent是怎么放到vm里面并且运行起来的?这个过程出现在https://github.com/RUB-SysSec/kAFL主页,需要自己封装一个vm,在里面运行loader agent,然后创建一个快照。
-
整个系统虚拟化的构建情况
fuzzing主要逻辑就是通过qemu-pt和kvm-pt交互来运行目标VMs。
关于物理cpu,逻辑cpu,虚拟化cpu的结构定义:物理cpu就是指硬件cpu,逻辑cpu指通过物理cpu衍生出来逻辑上的cpu,一个物理cpu可能对应多个逻辑cpu,当某一个时刻只有一个逻辑cpu在运行,而虚拟化的cpu是指,虚拟机使用的cpu,在逻辑cpu上又分化出来的东西
kvm-pt 和 qemu-pt交互主要用于inter pt的操作。kvm-pt给qemu-pt传输相关的trace信息,trace的解码过程发生在qemu里面,还涉及到trace相关的过滤问题。
-
如何利用intel PT?
首先通过一个特殊MSR(model speical register)IA32_RTIT_CTL_MSR.TraceEn 打开,然后做一些关于filter的选择。这个trace针对的是一个逻辑cpu,所以针对它的修改必须发生在cpu把host context切换到vm context上,关闭trace的操作即相反。
intel PT的需要一些配置项来支持,也是通过设置其他的MSR来完成的,为了避免收集一些不必要的trace信息,通过intel vt-x来在VM-entry和VM-exit来自动自动加载这些配置项。
那么存储trace信息的结构是什么?在配置的时候会选择一个物理地址,trace信息会不断的写入这个物理地址,直到被写满。这个buffer被一个叫 Table of Physical Addresses数组结构管理,这个数组可以存储很多元素,结尾有一个End 元素。
文中还考虑了一个溢出的问题,为了避免溢出造成的trace丢失,这里使用了两个ToPA元素,当一个被填充满时,会触发一个中断,当中断传递到位时可以接着使用第二个buffer,如果第二个buffer也被填满了,将直接导致trace 停止。第二个buffer大小的选择是作者在实践中遇到溢出最多的trace info的4倍。后面如果第二个够buffer被填满以后,可以动态的调整第二个buffer的大小来满足所有的trace 信息。
-
关于qemu-pt中相关patch的实践?
首先qemu作为fuzzer和kvm的中间连接点,如果想了解整个系统的过程,必须弄清楚qemu在其中的担任的角色。从fuzzer和qemu的交互开始,qemu-pt在注册了一个新的pci device,这个新的device负责在qemu的启动的时候,建立fuzzer和vm的联系。
"-chardev socket,server,nowait,path=" + self.control_filename + \qemu 通过这个本地的socket和 fuzzer进行交互。这个fuzzer只通过这个socket进行对qemu的行为控制,agent 二进制,bitmap,payload的传输还是通过shm来交互。
"-device kafl,chardev=kafl_interface,bitmap_size=" + str(self.bitmap_size) + ",shm0=" + self.binary_filename + \ ",shm1=" + self.payload_filename + \ ",bitmap=" + self.bitmap_filename -
VM-exit 之后kvm和qemu的交互是怎么样的?
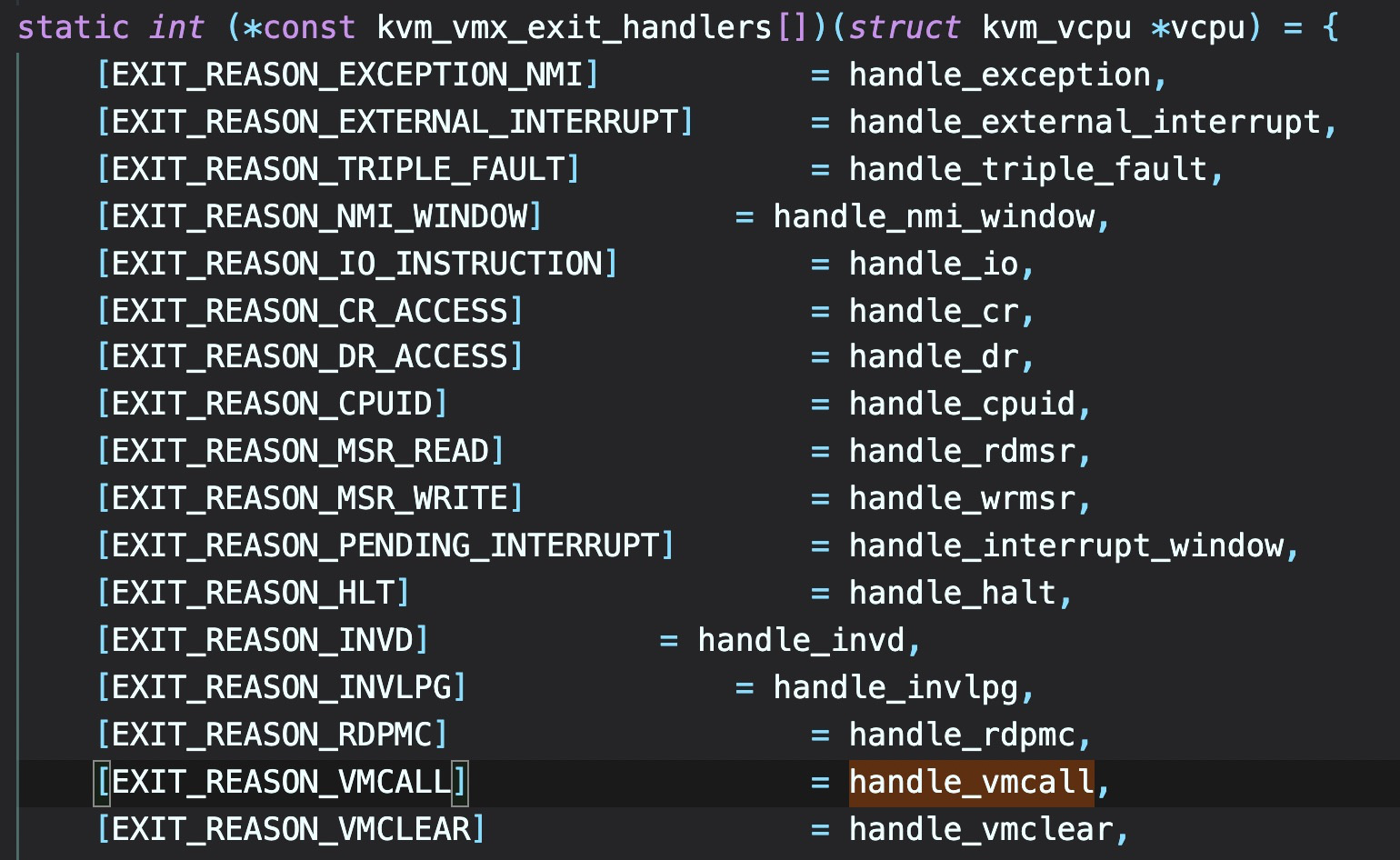
这个过程涉及到kvm的异常处理,例如当hypercall导致的VM-exit,kvm中vmx驱动有一个专门响应不同情况下VM-exit的handler:
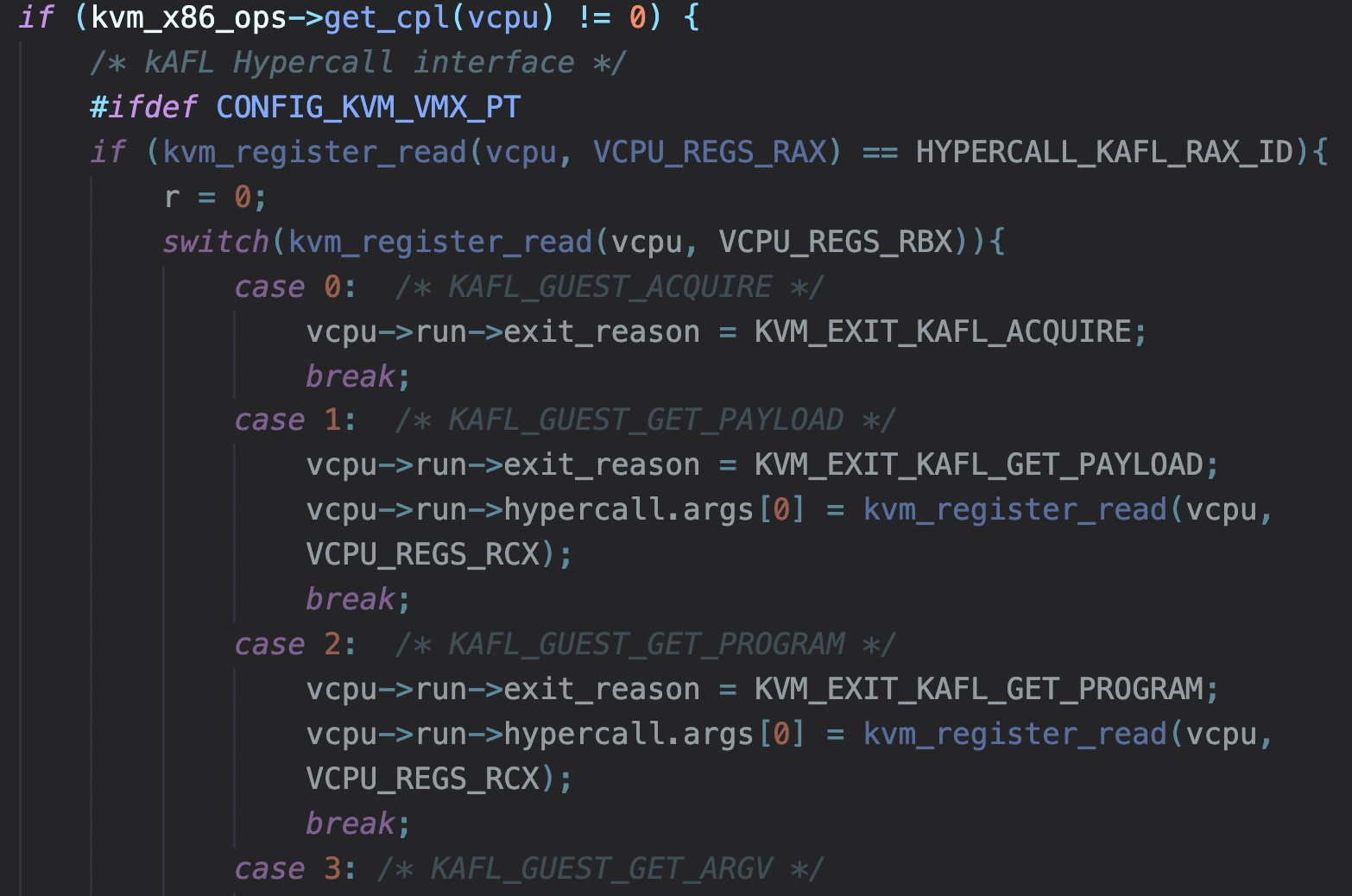
这里hypercall对应的就是handle_vmcall -> kvm_emulate_hypercall,在这个里面处理各种来自ring0或者ring3的hypercall。vmcall有几个相关的寄存器,其实类似syscall,以kafl打的patch为例:
这是一个处理来自ring3的请求,即agent的请求,rax里面代表kafl相关的hypercall,rbx则代表了agent的相关需要,其中exit_reason代表了VM-exit的原因,后面则是相关需要返回给qemu的参数值。
而在qemu里面有一个闭环,这个闭环发生在kvm_cpu_exec里面,这里闭环我简略成下面的形式:
do{ ... run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0); switch (run->exit_reason) { case KVM_EXIT_KAFL_ACQUIRE: handle_hypercall_kafl_acquire(run, cpu); ret = 0; break; case KVM_EXIT_KAFL_GET_PAYLOAD: handle_hypercall_get_payload(run, cpu); ret = 0; break; case KVM_EXIT_KAFL_GET_PROGRAM: handle_hypercall_get_program(run, cpu); ret = 0; break; ... } }while(ret==0)qemu就负责处理来自kvm的返回信息,处理完成,进而又让vm重新运行起来。
-
qemu是怎么把guest virtual address转化成在qemu可以写入(读)的地址?
kafl 整体上是qemu和kvm交互,然后在客户os里面放了一个agent,这个agent负责对客户机进行输入,同时接收来自qemu传递的payload,为了实现agent的功能,它们在kvm里面搞了几个特殊的ring3级别的hypercall。agent进行vmcall 系统调用的时候,这个vmcall和syscall类似会被kvm捕捉到。比如现在agent 需要payload输入了,就弄一个vmcall告诉kvm,同时附上这个输入payload的地址,这个地址就是客户机的虚拟地址,kvm捕捉到了这个hypercall把信息返回给了qemu,然后qemu要向这个客户机的虚拟地址(gva)写入payload。
在写的时候,我发现它里面逻辑似乎有点问题的,客户机的物理地址实际都是qemu的给定的,在对gva进行写入的时候,需要先把gva转化成客户机的物理地址(gpa),gpa就对应了qemu给定的宿主机的虚拟内存。
在写的时候,如果数据比较大,需要分页写入,因为x86里面的内存交换大小是0x1000。比如写入往0x10010写入0x2000的数据,首先要去找0x10000对应的客户机物理地址phyadr,然后往phyadr+0x10 写入 0x1000-0x10的大小的数据。 相对于写了0x900,还剩下0x1100,那么接下来需要去找0x11000对应的客户机物理地址,再循环写入。
但是看kafl里面qemu关于对客户机虚拟地址写入的相关代码:
bool write_virtual_memory(uint64_t address, uint8_t* data, uint32_t size, CPUState *cpu) { int asidx; MemTxAttrs attrs; hwaddr phys_addr; MemTxResult res; uint64_t counter, l, i; counter = size; while(counter != 0){ l = x86_64_PAGE_SIZE; if (l > counter) l = counter; kvm_cpu_synchronize_state(cpu); //cpu_synchronize_state(cpu); asidx = cpu_asidx_from_attrs(cpu, MEMTXATTRS_UNSPECIFIED); attrs = MEMTXATTRS_UNSPECIFIED; phys_addr = cpu_get_phys_page_attrs_debug(cpu, (address & x86_64_PAGE_MASK), &attrs); if (phys_addr == -1){ printf("FAIL 1 (%lx)!\n", address); return false; } phys_addr += (address & ~x86_64_PAGE_MASK); res = address_space_rw(cpu_get_address_space(cpu, asidx), phys_addr, MEMTXATTRS_UNSPECIFIED, data, l, true); if (res != MEMTX_OK){ printf("FAIL 1 (%lx)!\n", address); return false; } i++; data += l; address += l; counter -= l; } return true; }用我们之前的例子,这里的
size是0x2000,l的大小是页大小0x1000,按照第一个条件这里1是小于counter大小的,所以写入长度为l的大小0x1000,但是我们前面正常逻辑这里一个是写入0x900,因为是从0x10010开始的,写入0x1000超过了一张物理页的大小。所以这里还应该考虑一下剩余页大小,读的时候也有这个问题。 -
如何利用intel PT的数据来构造和AFL里面关联edge的bitmap?
这个其中详细技术细节在原论文中并没有太多的介绍,我自己通过翻intel 手册里面关于processor trace的相关资料,能大概的知道整个技术细节。首先需要从intel PT output的数据结构开始。在kafl中只重点关注三种packet:
- TNT : 条件分支,taken or ont taken
- TIP : 间接分支,异常,中断和其他分支或者事件的目的IP。
- FUP:异步事件(中断或者异常)的源IP。
后面两种其实合为一种,都是只管关注IP属性,简单介绍一下三种数据包的结构:
-
TNT :每个条件指令的token or not taken用1bit的1和0来表示,TNT又有两种分组:分为short TNT(1字节)和 long TNT(8字节),short TNT可以最多包含6个bit TNT,long TNT可以最多包含47bit TNT,结尾用1标志或者stop bit。
-
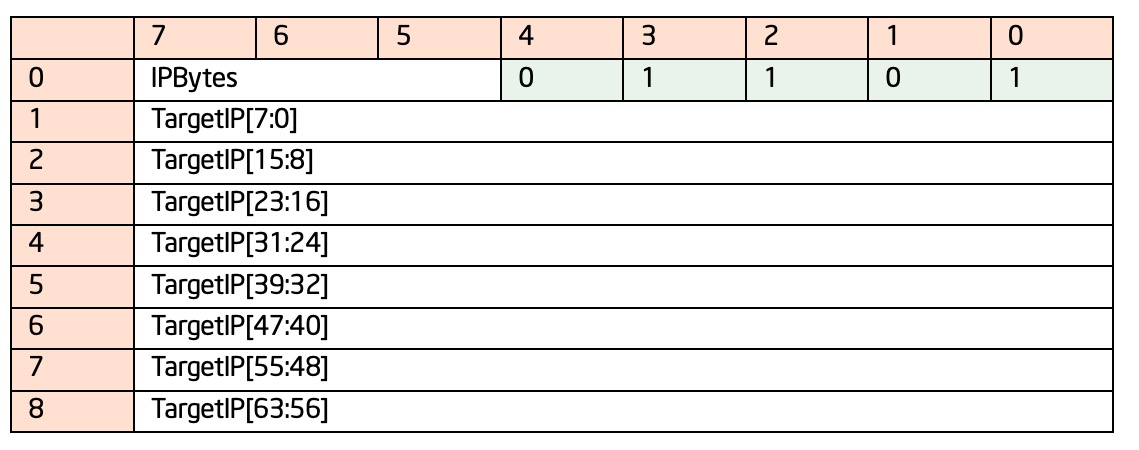
TIP:包大大小9字节,第一个字节包含TIP类型标示位和IP压缩的类型。
这个IP压缩策略,意味目标IP的大小是多样的,用IPBytes来表示压缩策略,IP压缩通过与上一次的IP相互进行比较来生成当前IP,比如上一次IP(last_ip)和这一次IP有同样的高位字节,就可以只记录一次高位字节,压缩的原理就在于压缩高位字节,所以decoder在解码的时候需要记录last_ip,来生成每一次TIP里面的经过压缩的IP真实数据,IP压缩策略有下面几种:
-
FUP的结构是TIP上一样的,这里就省略了。
可以通过intel手册上一个例子,来比较形象的体会这样的trace 信息。
可以看到上面三种trace信息中,是无法直接利用的,我们需要准确的指令位置和目标地址,当时intel trace信息是充分考虑了效率,对于条件分支为什么只需要记录taken 信息就够了?因为上面例子可以看到,对应的二进制指令是有准确的目标地址的,所以不需要再额外记录。所以这也是为什么qemu-pt中除了pt-decoder以为还需要,反汇编的阶段。
利用intel PT的ip filter功能,可以把trace 信息集中在某个具体的二进制中,就给我们的反汇编提供了地方。在qemu-pt也是这么做的:
buf = malloc(ip_b-ip_a); if(!read_virtual_memory(ip_a, buf, ip_b-ip_a, cpu)){ printf("FAIL 2\n"); free(buf); return -EINVAL; }再讲intel PT的trace 信息和反汇编的结构结合起来,就能准确的描述每一个分支指令所在的地址和目标地址,这样就有了edge,有了edge就可以翻译成AFL相关的bitmap。kafl在这里利用了一个map结构,把相关汇编指令结构缓存了起来,可以在第二次fetch相关指令的时候直接使用,减少了intel 直接出品的lib runtime dasm的消耗。
-
The input and crash handler of fuzzing kernel
-
对内核输入,取决于你要测试对像,例如你要测试文件系统,那么你输入就是需要挂在的文件映像,挂载过程通过agent来实现。
-
怎么捕获内核的crash 和 panic? 在kafl里面通过agent 找到相关kernel自身的异常处理handler地址,再把这个地址替换成自己的handler,这个过程通过hypercall来实现,比如在linux kernel下
loader agent 先找系统自身的错误处理,在通过hypercall发送给kvm,kvm再发给qemu:
panic_handler = get_address("T panic\n"); printf("Kernel Panic Handler Address:\t%lx\n", panic_handler); kasan_handler = get_address("t kasan_report_error\n"); if (kasan_handler){ printf("Kernel KASAN Handler Address:\t%lx\n", kasan_handler); } kAFL_hypercall(HYPERCALL_KAFL_SUBMIT_PANIC, panic_handler); if (kasan_handler){ kAFL_hypercall(HYPERCALL_KAFL_SUBMIT_KASAN, kasan_handler); }qemu把它们替换成ring0级别的hypercall:
/* * Panic Notifier Payload (x86-64) * fa cli * 48 c7 c0 1f 00 00 00 mov rax,0x1f * 48 c7 c3 08 00 00 00 mov rbx,0x8 * 48 c7 c1 00 00 00 00 mov rcx,0x0 * 0f 01 c1 vmcall * f4 hlt */ #define PANIC_PAYLOAD "\xFA\x48\xC7\xC0\x1F\x00\x00\x00\x48\xC7\xC3\x08\x00\x00\x00\x48\xC7\xC1\x00\x00\x00\x00\x0F\x01\xC1\xF4" /* * KASAN Notifier Payload (x86-64) * fa cli * 48 c7 c0 1f 00 00 00 mov rax,0x1f * 48 c7 c3 08 00 00 00 mov rbx,0x9 * 48 c7 c1 00 00 00 00 mov rcx,0x0 * 0f 01 c1 vmcall * f4 hlt */ #define KASAN_PAYLOAD "\xFA\x48\xC7\xC0\x1F\x00\x00\x00\x48\xC7\xC3\x09\x00\x00\x00\x48\xC7\xC1\x00\x00\x00\x00\x0F\x01\xC1\xF4"
-



0x03 自身的感受
这次搬论文,我没有从论文的结构开始搬,我先大概看了一下,心里总结了一些问题。然后我在去深入的解决这些问题,学到了非常多的东西,受用无穷。这样的论文太少了,没有比较华丽浮躁的技术,但是完整的构建了整个对于kernel的fuzzing系统,并且主要是有源码,在读源码过程中,真的太爽了。kafl是第二个对我受用无穷的东西(第一个给了angr和hopper,哈哈哈),希望我浅薄的理解能带给大家帮助!
