00 — Begin
和老五聊的比较久,最终还是答应他努力把自己平时的一些总结发在九零
不是不愿意发,而是感觉自己太菜,但是九零刚使用新论坛,内容欠缺,我也只能凑个数
本篇论文名为《Coverage-based greybox fuzzing as markov chain》,有三位作者:
Marcel Böhme
Computer Science, National University of Singapore, Singapore, Singapore Singapore 117417 (e-mail: [email protected])
Van-Thuan Pham
Computer Science, National University of Singapore, Singapore, Singapore Singapore (e-mail: [email protected])
Abhik Roychoudhury
Computer Science, National University of Singapore, Singapore, Singapore Singapore 117417 (e-mail: [email protected])
论文主要讨论的是系统安全测试中的Fuzzing技术
改进了著名前谷歌安全研究员 Michał Zalewski(ID: lcamtuf)写的模糊测试工具:AFL
01 – Why
目前绝大多数的Bug是由fuzzing Test发现的,Symbolic Execution仅占了小部分,因为fuzzing的速度更快,不需要进行程序内部逻辑分析,不需要进行相关的条件约束,而且对于受路径爆炸的影响来说更小。目前Fuzzing的挑战是,在一次模糊测试中,如果对一张有效的图片来进行fuzzing,那么执行fuzz后的图片,有90%的可能性执行拒绝无效图片文件的路径π,然后再fuzzing一张无效的图片文件,那么有99.999%的概率执行相同路径π。这样的路径π可以称作高频路径。简单来说,即许多fuzz会执行高频路径,导致大多数的模糊操作的路径是相同的,因此AFL-FAST提出了几种使模糊测试系统偏向低频路径的策略,以便在相同的模糊测试量下探索更多的路径。
02 - What
将AFL进行了改进,改进后的测试工具称为AFLFast
GitHub地址:
03 – How
AFL采用的方法就是找一些testcase,去触发漏洞或者提高代码的覆盖率,这里的部分的testcase也可以叫做seed(种子),这些种子通过循环不断去挑选好的种子,然后把好的种子留下来去进行下一轮测试,把种子编译好后,再进行测试,留下更好的种子,直到达到理想效果。
注: testcase不同于seed,优秀的对发现新coverage有利的testcase才能成为seed;大部分testcase都是被抛弃的
AFLFast在这里做的就是优化挑选种子的方法。通过查阅文献了解知道,AFL会经过每轮迭代挑选好的种子,然后把好的种子选出来一部分再进行变异杂交操作。
但需要注意,这里“好种子”不一定只有一个,可能几十,可能上百,如果第一轮迭代选第一个,第N轮迭代选择第N个,差别可能很大,所以种子的顺序非常关键,AFLFast做的工作是评估了这N个种子中,哪个种子被选了多少次,因为有的种子被选择的次数很大(高频路径),有的可能就一次(低频路径),AFLFast这时候会优先选择被选次数较小的种子,因为被选择次数多的种子被充分测试了,剩余价值就没有这个被选次数较少的价值高。
总的来说,由于AFL去执行高频路径,花费了大量时间,因此AFLFast改进了AFL的种子输入的选择策略和每个种子fuzz的次数的计算方法,从技术上讲,AFLFast修改了种子性能得分(calculate_score)的计算,该种子被标记为favorite(update_bitmap_score),并且接下来从循环队列(main)中选择了哪个种子。
AFLFast的具体做法如下所述。
搜索策略
即确定下一个所要选择的种子,这个决策依赖于种子之前被fuzz的次数、相同路径的数量,给低频路径更高的优先级。策略有两个标准:
- s(i)小的优先级高:s(i)表示种子t_i之前从队列 Τ 中选到的次数
- f(i)小的优先级高:f(i)表示执行路径 I 的生成输入的能量
能量分配策略
AFLFast将CGF视为马尔科夫链,假设当前种子输入执行的路径是 i ,fuzz之后的路径为 j 的概率为 P_{ij} 那么称路径从 i 到路径 j 所要生成的测试用例个数为该种子输入的能量( E_{ij}=1/P_{ij} )。
这里的 P_{ij} 通常是未知的,所以CGF对能量的分配也通常是经验性的,AFL采用的是一个常数,AFLFast则采用了几种新的分配策略:
首先AFLFast为Power Schedule定义了一个函数:
p(i)=\mathbb{E}[X_{ij}]
这里的 p(i) 是关于 s(i) 和 f(i) 的函数,其中 p(i) 是指种子 t_i 之前从队列 Τ 中选到的次数, f(i) 表示执行路径 i 的生成输入的能量。 f(i)/n 是CGF产生输入的概率的最大似然估计量。于是就有了以下几种power shcedules:
Exploitation-based constant schedule (EXPLOIT) : p(i)=α(i) ,其中 α(i) 是算法中assignEnergy的实现,AFL根据所执行的时间、块转换覆盖率以及 t_i 的构造时间来计算 α(i)
Exploration-based constant schedule (EXPLORE): p(i)= α(i)/β ,其中 α(i)/β 保持fuzz对t_i质量的原始判断 α(i) , β>1 是一个常数
Cut-Off Exponential (COE): \begin{cases}0 , f(i)>μ\\min(\frac{α(i)}{β}·2^{s(i)},M),其他情况\\\end{cases} ,其中 α(i) 保持模糊的原始判断, β>1 是一个常数, s(i) 值较低,μ是执行已发现路径的模糊平均数,且 \frac{∑_{iϵS^+}f(i) )}{| S^{+}|} , S^+ 是发现的路径集合,直观的说, f(i)>μ 为高频路径,即使从模糊其他种子接收大量模糊,也被视为低优先级,直到它们再次低于平均值才模糊。常数M提供了每次模糊迭代生成的输入数量的上限。
Exponential schedule (FAST) : min(\frac{α(i)}{β}·\frac{2^{s(i)}}{f(i)},M) ,当 f(i)>μ 时,Power Schedule不会使 t_i 模糊,而是使 t_i 和执行路径 i 的模糊 f(i) 的量成反比,分母中的 f(i) 利用过去没有收到大量模糊的 t_i ,因此更可能位于低频区域,这样, s(i) 的指数增长允许越来越多的能量用于低频路径。(个人理解就是输入队列中选择 t_i 的输入次数越多,执行路径 i 就越少,所以放在指数上, t_i 选的越多,就赋予低频路径越多的能量值,让其多变异。)
Linear schedule (LINEAR): min(\frac{α(i)}{β}·\frac{{s(i)}}{f(i)},M)
Quadratic schedule (QUAD): min(\frac{α(i)}{β}·\frac{{s(i)^2}}{f(i)},M)
对于每个种子输入fuzz的次数,在AFL原有计算结果的基础上,再乘以一个以指数增长的系数,然后设定一个最大值,如果超过了这个最大值,进行截断:
- 指数截断(COE)
- 快速截断(FAST)
- 线性规划(LINE)
- 二次规划(QUAD)
通过上述的策略,AFLFast智能地控制种子产生的模糊量,从而使搜索转向低频运行的路径,转向可能隐藏漏洞的路径。
04 – Code(具体代码如何改进的)
通过比对AFL(V2.32b)和AFLFast的源文件,发现以下文件进行了改动:
主目录下:
- afl-analyze.c (3处不同)
- afl-as.c (3处不同)
- afl-cmin (4处不同)
- afl-fuzz.c (104处不同)
- afl-gcc.c (3处不同)
- afl-plot (1处不同)
- afl-showamp.c (14处不同)
- afl-tmin.c (17处不同)
- afl-whatsup (1处不同)
- config.h (6处不同)
- Makefile (2处不同)
- types.h (1处不同)
dictionaries目录下:
- json.dict (新增)
experimental/crash_triage目录下:
- triage_crashes.sh (2处不同)
experimental/distributed_fuzzing目录下:
- sync_script.sh (1处不同)
libdislocator目录下:
- libdislocator.so.c (6处不同)
libtokencap目录下:
- libtokencap.so.c (2处不同)
llvm_mode目录下:
- afl-clang-fast.c (6处不同)
- afl-llvm-pass.so.cc (5处不同)
- afl-llvm-rt.o.c (9处不同)
经过进一步对比,发现主要是afl-fuzz.c进行了较大的改动,其他文件根据afl-fuzz.c的改动而略微改动。在afl-fuzz.c文件中,改动如图1:
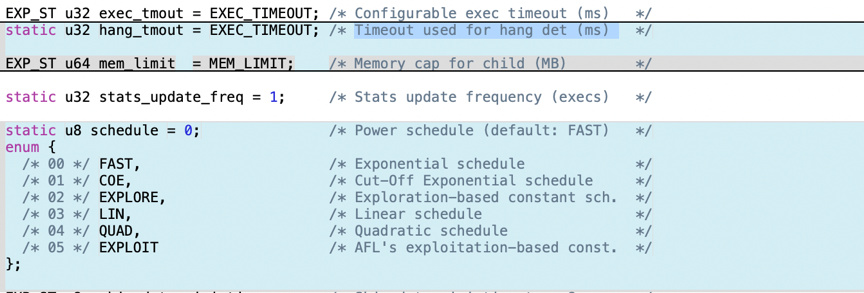
图1
从图一可以看出,AFLFast建立了一个新的能量分配模块,其中FAST代表文章中的快速截断、COE代表指数截断、EXPLORE代表Exploration-based constant schedule、LIN代表线性规划、QUAD代表二次规划、EXPLOIT代表Exploitation-based constant schedule。
此外,还给模糊迭代次数专门创建变量为fuzz_level,不发生溢出的模糊次数创建变量为n_fuzz,如图2。
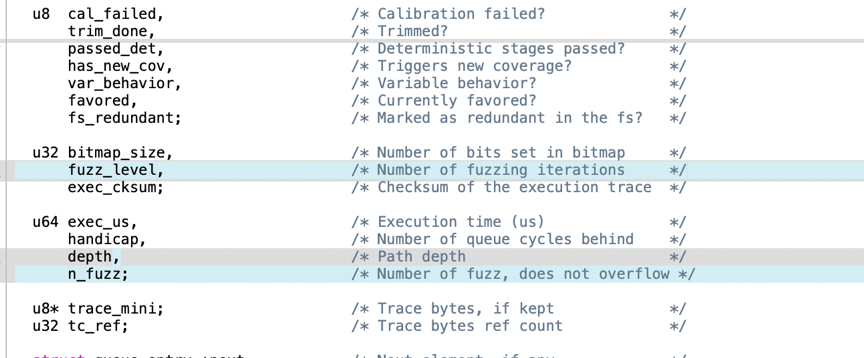
图2
在图3中,可以看到代码主要改变了下一个种子输入的策略,给了两种策略:一种优先考虑 s(i)最小的执行路径 i 的输入,一种是优先考虑 f(i) 最小的执行路径 i 的输入。
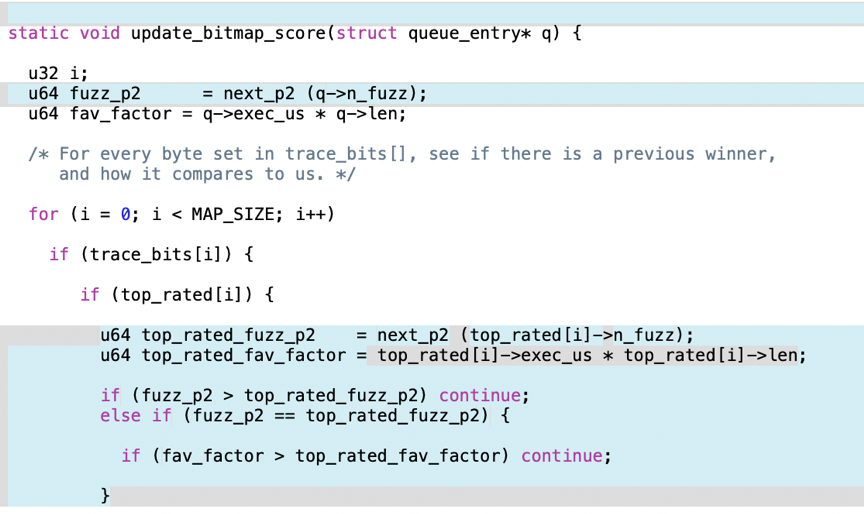
图3
在为每个路径片段选择“favorite”输入时,先用s(i)策略,如果不止一个,再用f(i)策略;如果还有,则使用AFL的策略。
在为当前的输入选择下一个“favorite”输入时,采用同样的流程
在图4中,可以看到AFLFast新增了更新高频路径的判断。
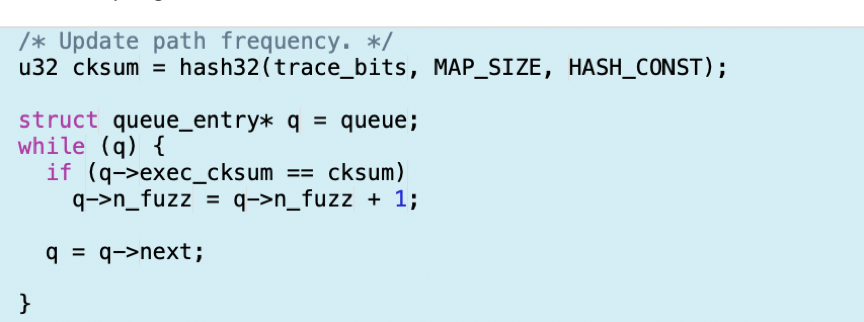
图4
图5也是一处比较大的变动,但是读了注释后也不是很明白是用来干什么用的(论文对应的地方没找到)。
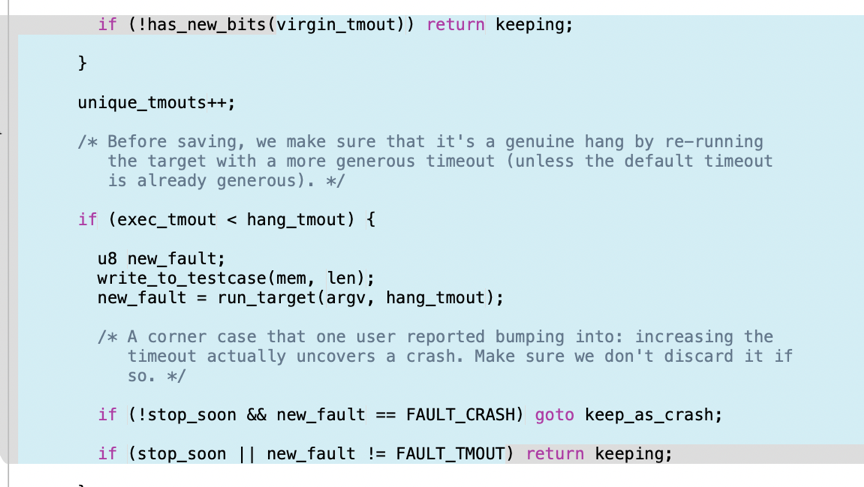
图5
如图6、7、8,这里是文件最大的改动了,是能量分配的具体实现:

图6
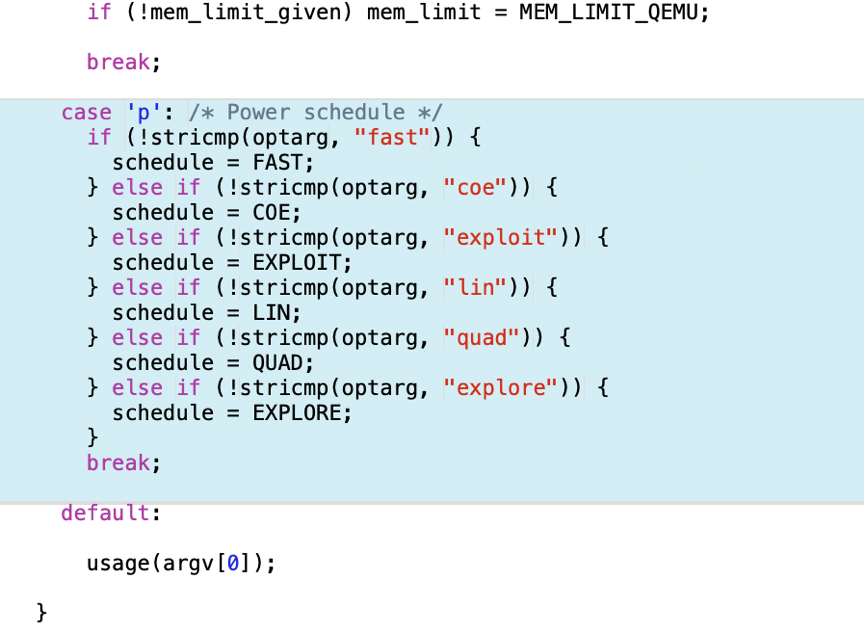
图7

图8
05 – Result
- 在GNU binutils中发现了9个CVE
- AFLFAST暴露6个CVE的速度是AFL的14倍
- 开源了AFLFast
06 - Reference
GitHub - mirrorer/afl: american fuzzy lop (copy of the source code for easy access)
https://www.jianshu.com/p/4bd82c28e267
https://bbs.pediy.com/thread-249912.htm
Coverage-based Greybox Fuzzing as Markov Chain · cgnail's weblog
Coverage-based Greybox Fuzzing as Markov Chain-CSDN博客