Fuzzing Error Handling Code using Context-Sensitive Software Fault Injection
0x00 Introduction
Why should fuzzing error handling code?
因为有一些bug存在于错误和异常处理当中,而且想要fuzzing覆盖错误处理,实际上是比较难。
just a challenge,nothing else!
History
static analysis 容易造成很多的false positives(缺少运行时的信息, reachable?),为了减少false positives,开始尝试用fuzzing来解决问题,简单的input-driven只能在一定程度上解决问题,因为存在一些异常并不依赖输入。基于直觉的*software fault injection (SFI)*运营而生,尝试人为的注入一些错误和异常,观察程序在运行时是否能正常的捕获这些错误和异常。
现存的一些SFI技术,通常采用是context insensitive fault injection,这种技术单纯地静态在某一些位置注入异常或者错误,可能会导致程序每次执行到该位置时都会触发错误,而导致一些其他行为,例如程序可能就直接exit,这样的情况下可能会错过一些real bugs,引用文中的例子:

采用上下文不敏感的方法在FuncP中的malloc注入错误,将会导致在调用FuncB时就直接退出了,而你就会错过调用FuncB而导致的double-free。试想有选择性地在FuncP的malloc中注入错误,将会有机会捕获到这个异常(第一个疑问when injects? )。
Bug Examples in Error Handling Code
文中有一个例子举的很好,一下直观的说明了解决这个问题的意义:

在patch之前很明显这是UAF ,但是触发这个UAF必须先进入上这个if,文中提到必须在av_frame_new_side_data在申请内存失败,才会进这个if,这下子文章的整个主题*“bugs in error handling code”就变得有意义起来了,有些异常的触发极有可能不依赖于输入,文中将异常分为了两类:1) input-related error 和 2) occasional error,第一类好理解,输入相关,第二类通常为内存或者网络引发的错误。为了触发第二类异常,需要改变改变mutate对象,结合Fuzzing* 和fault injection可以擦出怎样的灿烂火花?
0x01 Basic Idea and Approach
Basic idea
为了实现Fuzzing和fault injection结合,文中构造了一个error sequence,其中包含多个error point,一个error point表示异常和错误可达且可被捕获,当使用fault injection可以决定每一个error point是否触发错误和异常,类似一个选择开关,形式化的表示如下:
类似程序输入,同样影响着程序执行,其中核心问题变成了“哪些error point应该被触发?使其能覆盖尽可能多的异常处理代码“,在这里插入Fuzzing的思想,把mutation作用到error sequence,来解决这个核心核心。
Error Sequence Model
基础定义:
context insensitive error point: ErrPt = <ErrLoc> (单纯用error site来描述)
context sensitive error point: ErrPt = <ErrLoc, CallCtx> (在error site的基础上,添加了运行时的调用栈来表示上下文)
其中 CallCtx = [CallInfo_1,CallInfo_2,\ldots,CallInfo_x]
每一次函数调用包括caller和calle, CallInfo_i=<CallLoc,FuncLoc>
FIFUZZ
FIFUZZ就是原文提出的一种针对上面问题的context sensitive fault injection解决方法。它由6个步骤组成:
- statically identifying the error sites in the source code of the tested program (静态地识别被测程序源码中的error sites)
- running the tested program and collecting runtime information about calling contexts of each executed error site and code coverage (在运行时收集error site执行时的上下文和覆盖率)
- creating error sequences about executed error sites according to runtime information, and each element of such a sequence is differentiated by the location of the executed error site and the information about its calling context (利用收集到的运行时的error point信息,构造用于执行mutation和fault inject的错误序列,)
- after running the program, mutating each created error sequence to generate new sequences (迭代生成新的错误序列)
- running the tested program and injecting faults according to the mutated error sequences (继续跑输入,并且在运行时执行fault injection)
- collecting runtime information, creating new error sequences and performing mutation of these error sequences again, which constructs a fuzzing loop (循环往复)
error side定义是指注入的fault可以被正常触发和捕获的位置(code location)
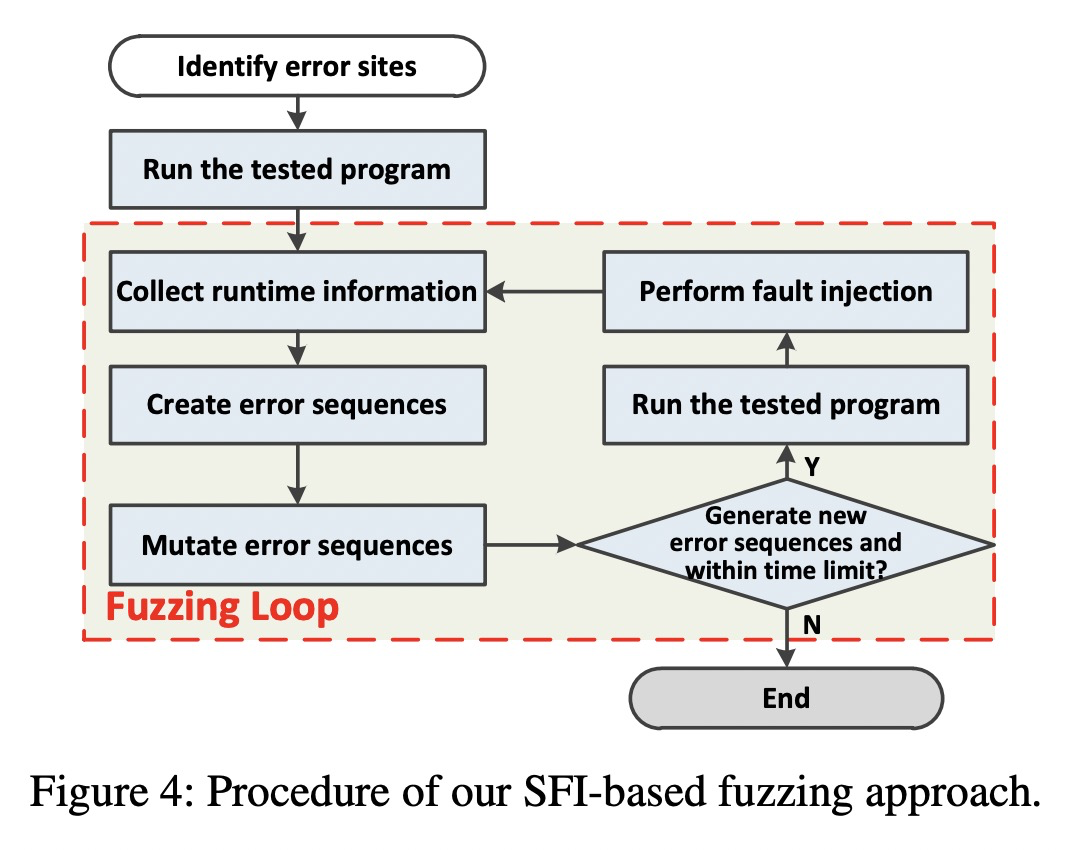
我从直觉上猜测的是,通过instrument标记error side,一次运行程序,得到可以被覆盖的error side,并不是简单的count,应该是有上下文敏感的count,通过得到这个信息,构造一个error sequence序列,表示应该去触发哪些error side。
文中整个Fuzzing Loop的不同于一般情况下,mutation的对象重点关注错误序列,还有一个问题哪些因素会去影响mutation?其实还是覆盖率,只是变成了error sequence带来的覆盖率,如果一次error sequence可以带来新覆盖率,就把它加到mutation过程的pool里面(还有一个优先级的东西,但是太模糊,“贡献的覆盖率”是指这个error sequence完整的覆盖率,还是在prev error sequence上增长的覆盖率,显然后一种似乎并没有什么道理)。
Fuzzing Loop有一个初始化的过程,因为第一次跑程序的时候,其实是没有反馈的信息的,构造了下面一个初始化的mutation过程,initial error sequence每个error point都是0,然后把它拆开成多个error sequence,其中每个error sequence都只有一个error point是1,且每个error sequence是唯一的。
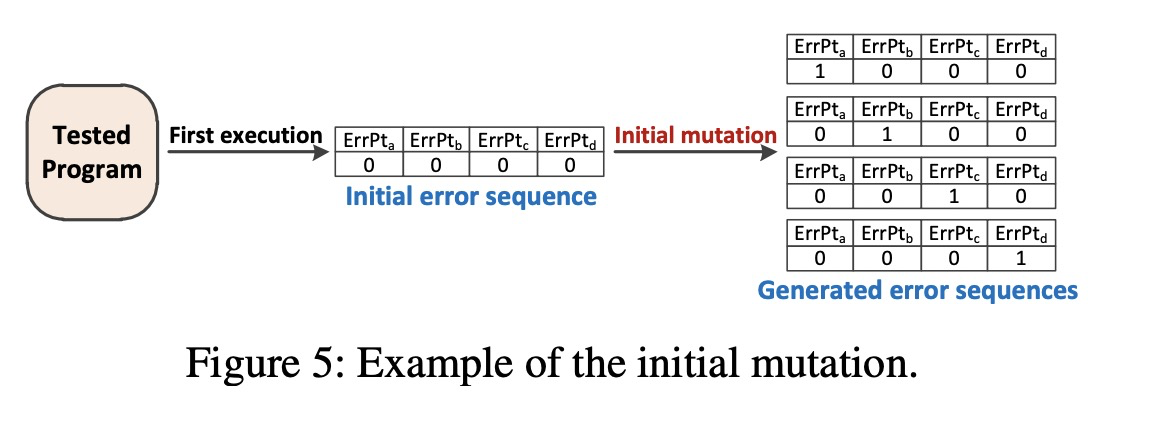
后面的迭代过程基于覆盖率,mutation尝试将mutate每一个error point(1 \rightarrow 0 \ or\ 0 \rightarrow 1) ,整个过程并无亮点,我觉得难点在于怎么在动态根据上下文做到的fault injection? 和 如何做到的同时mutate程序输入和错误序列?
How to identity error side?
这一章节是第一次接触fault injection的人应该最想要知道的,用它的时候,你必须保证你触发的错误是实际中存在的,不然造成的false positive是没有任何意义的。文中尝试通过静态分析的方法去识别error side,更具体一点,一个特殊的函数调用可能变成一个error side,其unexpect的返回值可能触发异常和错误处理,所以识别error side的粒度其实以函数为标准,具体分析过程如下:
-
Identifying candidate error sites :在大多数情况下,函数返回值为空指针或者负值时,表示一个failure,如果一个函数调用可能是一个error side,从两个方面来看:1)如果它的返回值类型为指针或者整型;2)它的返回值流到if上,并且检查其值是否为NULL或者zero。
-
Selecting library functions: 在大多数情况下,异常和错误产生于外部的库函数,从这个角度出发,如果定义在当前程序中的函数可能触发异常和错误,代表着它作用域下库函数可能会触发异常和错误。这个描述太过于模糊,应该建立函数的返回值和库函数(可能触发异常和错误)的联系。
-
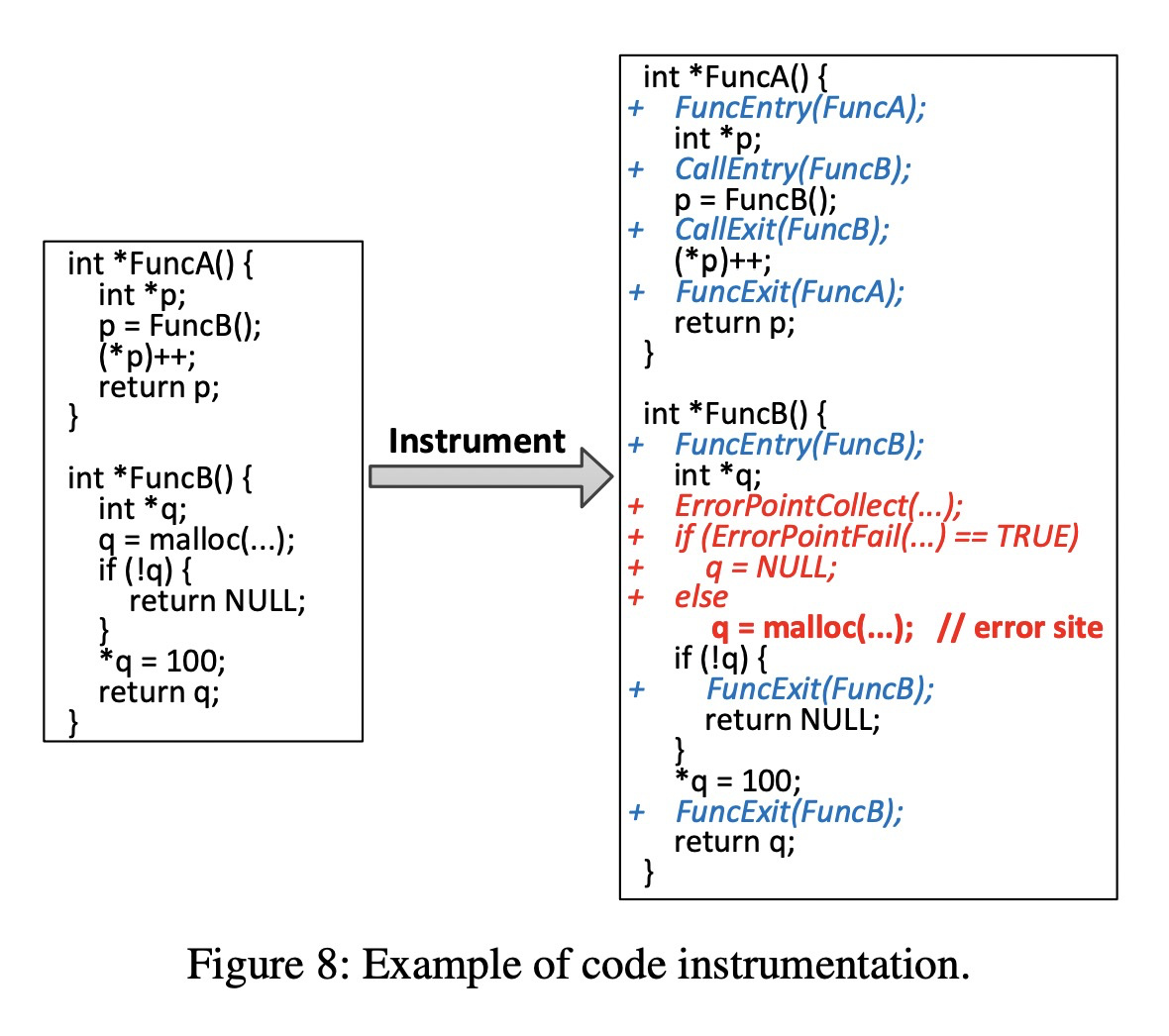
这一步不太容易理解,我尝试用我的理解来讲一下(可能并不是原文的意思,读者需斟酌),第一步确定了候选的函数调用,需要进一步确定这些函数调用的目标函数返回值是否受错误和异常的影响?第二步给了一个最基础的标准,我们可以已知的库函数会引发错误和异常,通过这些库函数再去迭代标识,程序中定义的函数是否可能引发错误和异常?这两个步骤已经可以基本确定一些error side了,然后再这些error side处做一些特殊的instrument,如下:
注意红色的部分,当指定的error point被触发时(需要检查上下文),将被标记为error side的函数调用替换成NULL或者zero,让其触发异常处理。但是第二步描述的非常模糊(个人觉得),只能识别一部分函数可能导致错误和异常,为了尽可能多的识别error function,在第三步这里用了一个统计方法,如果某个函数调用在候选的error side,在程序中全局搜索所有该函数调用的数量 S ,其中该函数调用的返回值进入if数量为 s_j ,且 s_j/S > R ,则认为该函数调用的目标函数是一个error function, R 代表一个阀值,如果 R 越大,导致error function越少,随之error side越少, R 的适配需要根据被测程序的实际情况来决定。
int Func_a(){ p = maybeTriggerError(...); if(!p){ //error handling } .... } int Func_b(){ maybeTriggerError(...); ... //maybe error handling }
0x02 Self Conclusion
有意思的一篇文章,改变了mutation的对象,在这里我总结了几个我想要知道的问题:
- fault injection是个什么东西?如何确定error side?
- 文中新的mutation对象error sequence是如何构造的?
- 如何在动态运行时根据上下文做到的fault injection?
- 如何做到的同时mutate程序输入和错误序列?(相互协调)
这几个问题都在前面有描述了,但是4文中没有提到,Fuzzing Loop反馈驱动比较常规,重点在于如何连续的Perform Software fault injection?