最近刚接触了研究验证码对抗
刚好朋友说想搞somd5 批量查询 但是卡在了滑块验证码 的认证上
于是:盘他
学习了几篇别的大佬的操作 也有了几个尝试
尝试:
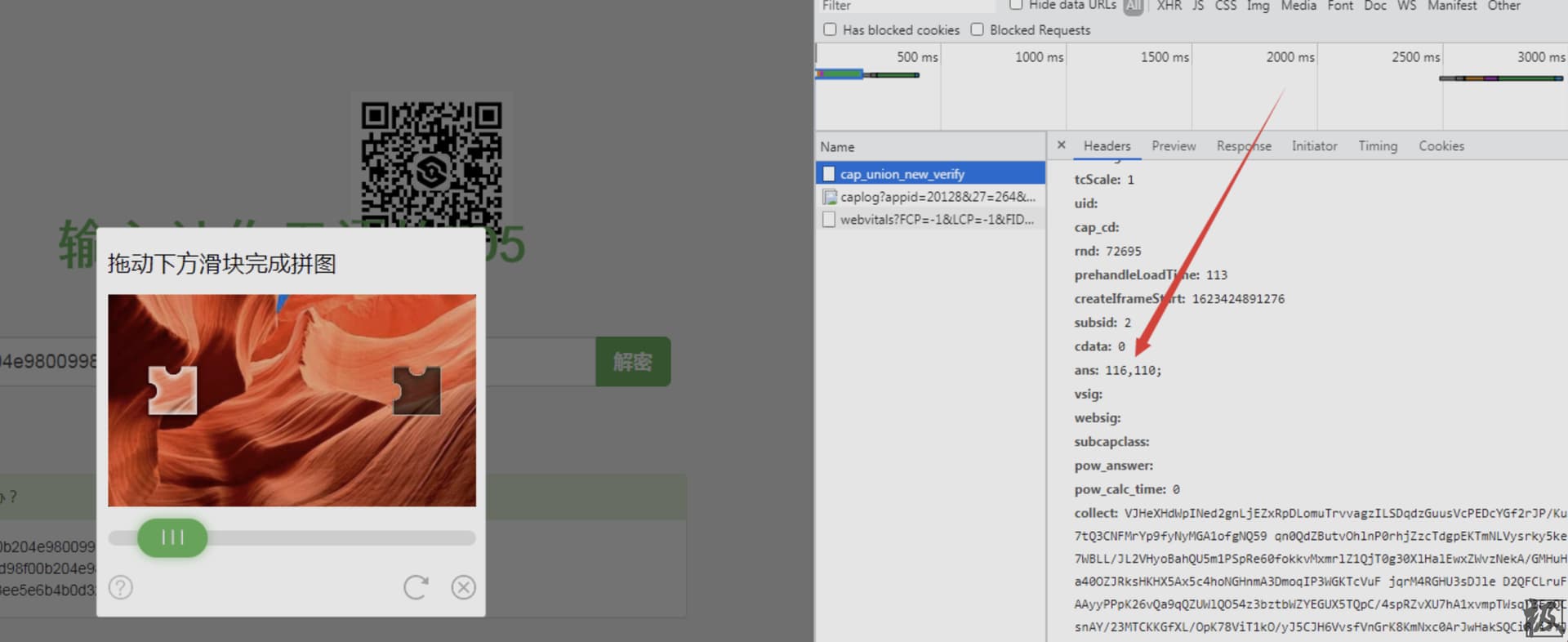
采集信息:


移动了两次 发现ans 的后面的值 (110 )始终没有变
然后这个滑块 x,y值中的Y始终是水平的
所以猜ans是坐标
只要传入缺口的坐标 即可(缺口左上角顶点坐标
这里用cv2 ,网上借鉴 了一下(读书人的事那能叫抄吗
def identify_gap(beijing,quekou):
'''
beijing: 背景图片
quekou: 缺口图片
'''
# 读取背景图片和缺口图片
beijing_img = cv2.imread(beijing) # 背景图片
quekou_img = cv2.imread(quekou) # 缺口图片
# 识别图片边缘
beijing_edge = cv2.Canny(beijing_img, 100, 200)
quekou_edge = cv2.Canny(quekou_img, 100, 200)
# 转换图片格式
beijing_pic = cv2.cvtColor(beijing_edge, cv2.COLOR_GRAY2RGB)
quekou_pic = cv2.cvtColor(quekou_edge, cv2.COLOR_GRAY2RGB)
# 缺口匹配
res = cv2.matchTemplate(beijing_pic, quekou_pic, cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # 寻找最优匹配
# 绘制方框
th, tw = quekou_pic.shape[:2]
tl = max_loc
# 返回缺口的坐标(x
return tl[0]
然后return 的 就是左上角缺口顶点的x (因为只需要x就可以计算偏移量
但是由于我人傻 不知道怎么解决verify的请求问题 所以就放弃了直接request这条路,改用selenium(嘻嘻),有兴趣的表哥可以试试
使用selenium
def init():
options = Options()
options.binary_location = "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" #chrome binary location specified here
options.add_argument("-enable-webgl")
options.add_argument("--no-sandbox") #bypass OS security model
options.add_argument("--disable-dev-shm-usage") #overcome limited resource problems
driver = webdriver.Chrome(options=options, executable_path=r'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
driver.get('https://www.somd5.com/')
return driver
def download(url,file):
r = requests.get(url)
with open(file, "wb") as code:
code.write(r.content)
def search(driver,md5):
# 定位查询按钮
username = driver.find_element_by_id('hash')
username.clear()
username.send_keys(md5)
sleep(1)
# 定位登录按钮
btn = driver.find_element_by_id('TencentCaptcha')
btn.click()
sleep(1)
# 定位 iframe
frame = driver.find_element_by_xpath(xpath='//iframe')
# 切换到 iframe
# driver.switch_to_frame(frame) # 这个方法也可以运行,但是会报错
sleep(2)
driver.switch_to.frame(driver.find_element_by_xpath("/html/body/div[5]/iframe"))
# 定位滑动块
test_button = driver.find_element_by_xpath('//*[@id="tcaptcha_drag_thumb"]')
#获取大图 and 缺口 url
big_img=driver.find_element_by_xpath('/html/body/div/div[3]/div[2]/div[1]/div[2]/img').get_attribute("src")
small_img=driver.find_element_by_xpath('/html/body/div/div[3]/div[2]/div[1]/div[3]/img').get_attribute("src")
download(big_img,'big_img.jpg')
download(small_img,'small_img.png')
#print(big_img,small_img)#输出大图 & 缺口链接
# 实例一个动作链对象
action = ActionChains(driver)
action.click_and_hold(on_element=test_button).perform()#抓住滑块
action.move_by_offset(xoffset=(identify_gap('big_img.jpg','small_img.png')-52)/2, yoffset=0).perform()#滑动
test_button.click()
#print(identify_gap('big_img.jpg','small_img.png')) #输出680px的情况下的x坐标
sleep(6)
result=driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[2]/div[2]/div/div[2]').get_attribute("innerHTML")
return result
# 松开滑动
大功告成!完整代码如下
使用时切记把要查的内容放在md5.txt里
from selenium.webdriver import ActionChains
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.options import Options
import requests
import cv2
def init():
options = Options()
options.binary_location = "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" #chrome binary location specified here
options.add_argument("-enable-webgl")
options.add_argument("--no-sandbox") #bypass OS security model
options.add_argument("--disable-dev-shm-usage") #overcome limited resource problems
driver = webdriver.Chrome(options=options, executable_path=r'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')#改成自己的chromedriver所在位置
driver.get('https://www.somd5.com/')
return driver
def download(url,file):
r = requests.get(url)
with open(file, "wb") as code:
code.write(r.content)
def identify_gap(bg,tp):
'''
bg: 背景图片
tp: 缺口图片
'''
# 读取背景图片和缺口图片
bg_img = cv2.imread(bg) # 背景图片
tp_img = cv2.imread(tp) # 缺口图片
# 识别图片边缘
bg_edge = cv2.Canny(bg_img, 100, 200)
tp_edge = cv2.Canny(tp_img, 100, 200)
# 转换图片格式
bg_pic = cv2.cvtColor(bg_edge, cv2.COLOR_GRAY2RGB)
tp_pic = cv2.cvtColor(tp_edge, cv2.COLOR_GRAY2RGB)
# 缺口匹配
res = cv2.matchTemplate(bg_pic, tp_pic, cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # 寻找最优匹配
# 绘制方框
th, tw = tp_pic.shape[:2]
tl = max_loc
# 返回缺口的坐标(x
return tl[0]
def search(driver,md5):
# 定位查询按钮
username = driver.find_element_by_id('hash')
username.clear()
username.send_keys(md5)
sleep(1)
# 定位登录按钮
btn = driver.find_element_by_id('TencentCaptcha')
btn.click()
sleep(1)
# 定位 iframe
frame = driver.find_element_by_xpath(xpath='//iframe')
# 切换到 iframe
# driver.switch_to_frame(frame) # 这个方法也可以运行,但是会报错
sleep(2)
driver.switch_to.frame(driver.find_element_by_xpath("/html/body/div[5]/iframe"))
# 定位滑动块
test_button = driver.find_element_by_xpath('//*[@id="tcaptcha_drag_thumb"]')
#获取大图 and 缺口 url
big_img=driver.find_element_by_xpath('/html/body/div/div[3]/div[2]/div[1]/div[2]/img').get_attribute("src")
small_img=driver.find_element_by_xpath('/html/body/div/div[3]/div[2]/div[1]/div[3]/img').get_attribute("src")
download(big_img,'big_img.jpg')
download(small_img,'small_img.png')
#print(big_img,small_img)#输出大图 & 缺口链接
# 实例一个动作链对象
action = ActionChains(driver)
action.click_and_hold(on_element=test_button).perform()#抓住滑块
action.move_by_offset(xoffset=(identify_gap('big_img.jpg','small_img.png')-52)/2, yoffset=0).perform()#滑动
test_button.click()
#print(identify_gap('big_img.jpg','small_img.png')) #输出680px的情况下的x坐标
sleep(6)
result=driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[2]/div[2]/div/div[2]').get_attribute("innerHTML")
return result
# 松开滑动
if __name__=='__main__':
driver=init()
f = open("md5.txt")
line = f.readline()
while line:
result=search(driver,line)
with open('result.txt','a+') as q:
q.write(line.strip('\n')+"的查询结果:"+result+'\n')
line = f.readline()
f.close()
下载
然后就能实现了: