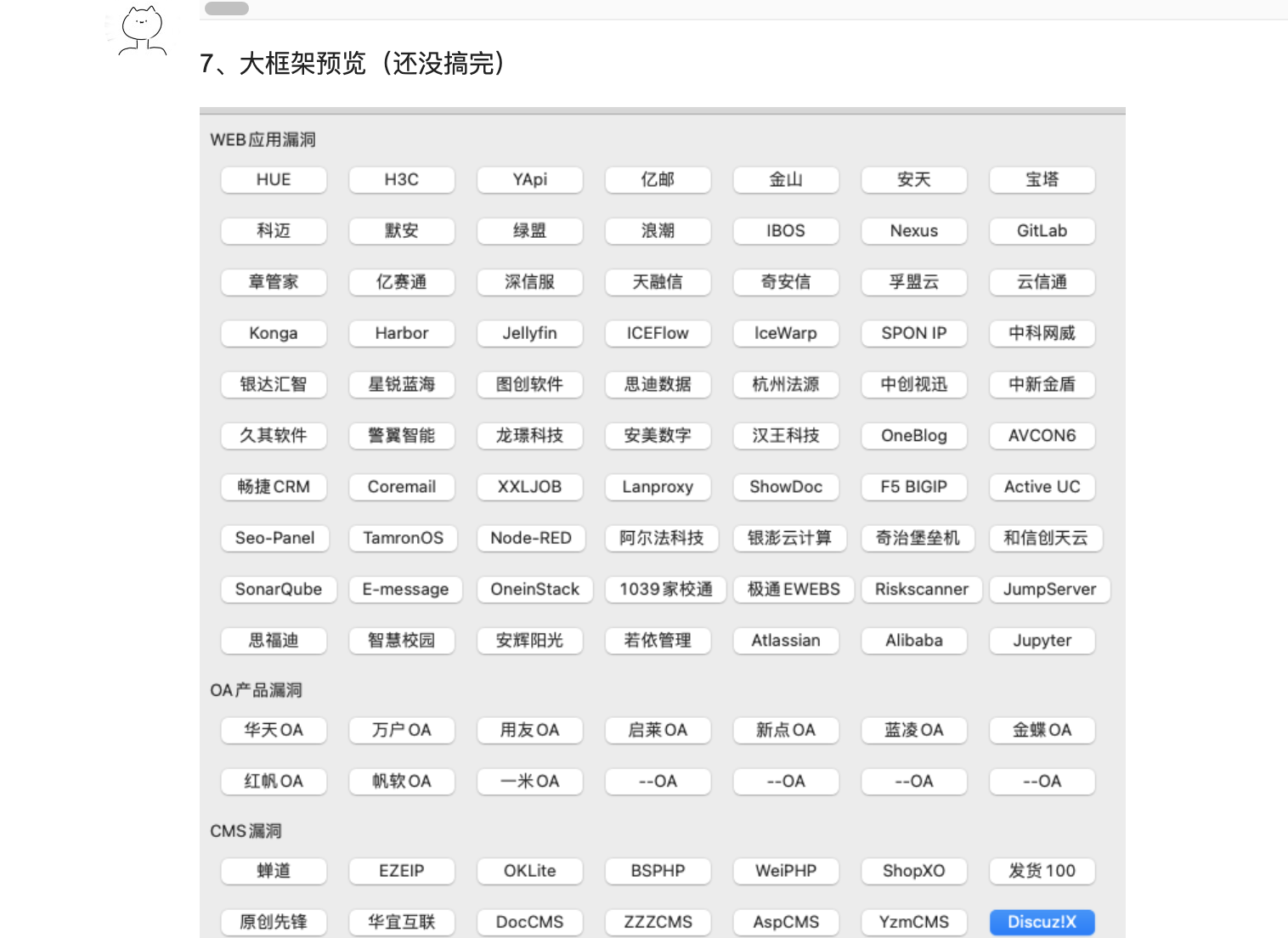
微信公众平台对接漏洞资讯
自定义服务器
1、登录微信公众平台
2、设置与开发-->基本配置
3、启用服务器配置

4、设置token
WECHAT_TOKEN = 'XXXXX' # token用来可微信公众平台对接 无限制只要与微信公众平台服务器配置处的一致即可
5、配置接口信息
app = Flask(__name__)
@app.route('/wx', methods=['GET', 'POST']) #/wx是我的路径 可以自己定义
6、判断是否对接成功
def wechat():
# 获取参数
signature = request.args.get('signature')
timestamp = request.args.get('timestamp')
nonce = request.args.get('nonce')
# echostr = request.args.get('echostr')
# 校验参数
if not all([signature, timestamp, nonce]): # echostr
abort(400)
# 签名加密
li = [WECHAT_TOKEN, timestamp, nonce]
# 列表排序重组加密
li.sort()
# 拼接字符
tem_str = "".join(li)
# sha1加密,以下步骤很重要
s1 = hashlib.sha1()
s1.update(tem_str.encode('utf8'))
sigin = s1.hexdigest()
# 签名值对比,相同证明请求来自微信
# 错误返回403页面
if signature != sigin:
abort(403)
else:
# 正确返回echostr字符串
# 表示是微信请求
if request.method == 'GET':
# 第一次接入服务器
echostr = request.args.get('echostr')
if not echostr:
abort(403)
else:
return echostr
elif request.method == 'POST':
# 表示微信服务器转发消息到本地服务器
xml_str = request.data
# print(xml_str)
if not xml_str:
return abort(403)
# 对xml字符串进行解析
xml_dict = xmltodict.parse(xml_str)
xml_dict1 = xml_dict.get('xml')
# print(xml_dict1)
# 提取消息类型
msg_type = xml_dict1.get('MsgType')
# print(msg_type)
7、读取用户输入的微信消息
if msg_type == 'text':
#判断接收到消息是不是文本
# 这是文本消息
# 构造返回值,由为微信服务器回复消息
# 重点:以下参数值一个不能少,一个字母不能错,大小写不能错,键名必须完全一样
inputdata = xml_dict1.get('Content')
#获取用户输入的字符
inputdata = str(inputdata)
#1⃣以字符串的方式存储
data = news.getdata(inputdata)
#调用函数获取redis数据库中的数据并生成URL返回给用户
resp_dict = {
"xml": {
'ToUserName': xml_dict1.get('FromUserName'),
'FromUserName': xml_dict1.get('ToUserName'),
'CreateTime': int(time.time()),
'MsgType': 'text',
'Content': data,
}
}
8、新用户关注微信回复消息
elif msg_type == 'event':
#判断用户操作,如果是关注,就回复data的内容
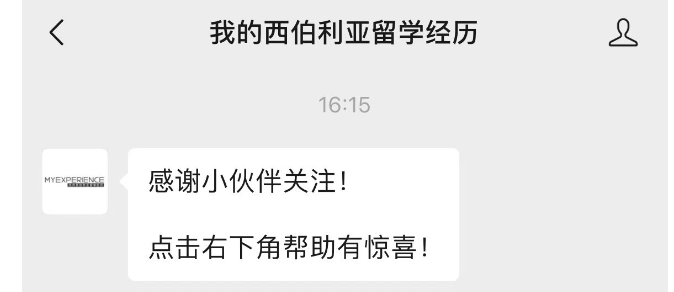
data = "感谢小伙伴关注!" + "\n" + "\n" + "点击右下角帮助有惊喜!"
if 'subscribe' == xml_dict1.get('Event'):
resp_dict = {
"xml": {
'ToUserName': xml_dict1.get('FromUserName'),
'FromUserName': xml_dict1.get('ToUserName'),
'CreateTime': int(time.time()),
'MsgType': 'text',
'Content': data
}
获取阿里云漏洞库数据到redis
1、连接数据库
connent = redis.Redis(host='127.0.0.1', port=6379,db=6)
2、采集CVE和非CVE漏洞(这里偷懒了 页面的话手动输入以下反正只采一次,嫌麻烦的话正则取一下吧!)
for page in range(1, 2836):
# 采集第一页到2836页,第一次数据采集的时候需要对照漏洞库的页数 手动输入 第一次采集完成 以后就不用了
url = f'https://avd.aliyun.com/nonvd/list?page={page}'
#非CVE漏洞库地址https://avd.aliyun.com/nonvd/list?page=
#CVE漏洞库地址https://avd.aliyun.com/nvd/list?page=
3、这一块的功能就是把采集的数据写入到redis中
rt = {'编号':number,'漏洞名称':name,'披露日期':date,'漏洞描述':describe,'整改建议':proposal,'等级':level}
#键值对 数据来是上面爬的
idkey = date + name
#redise hash命名 为了方便后面判断 所以这里以时间和漏洞名称组合取名
connent.hmset(idkey, rt)
#hmset写入值
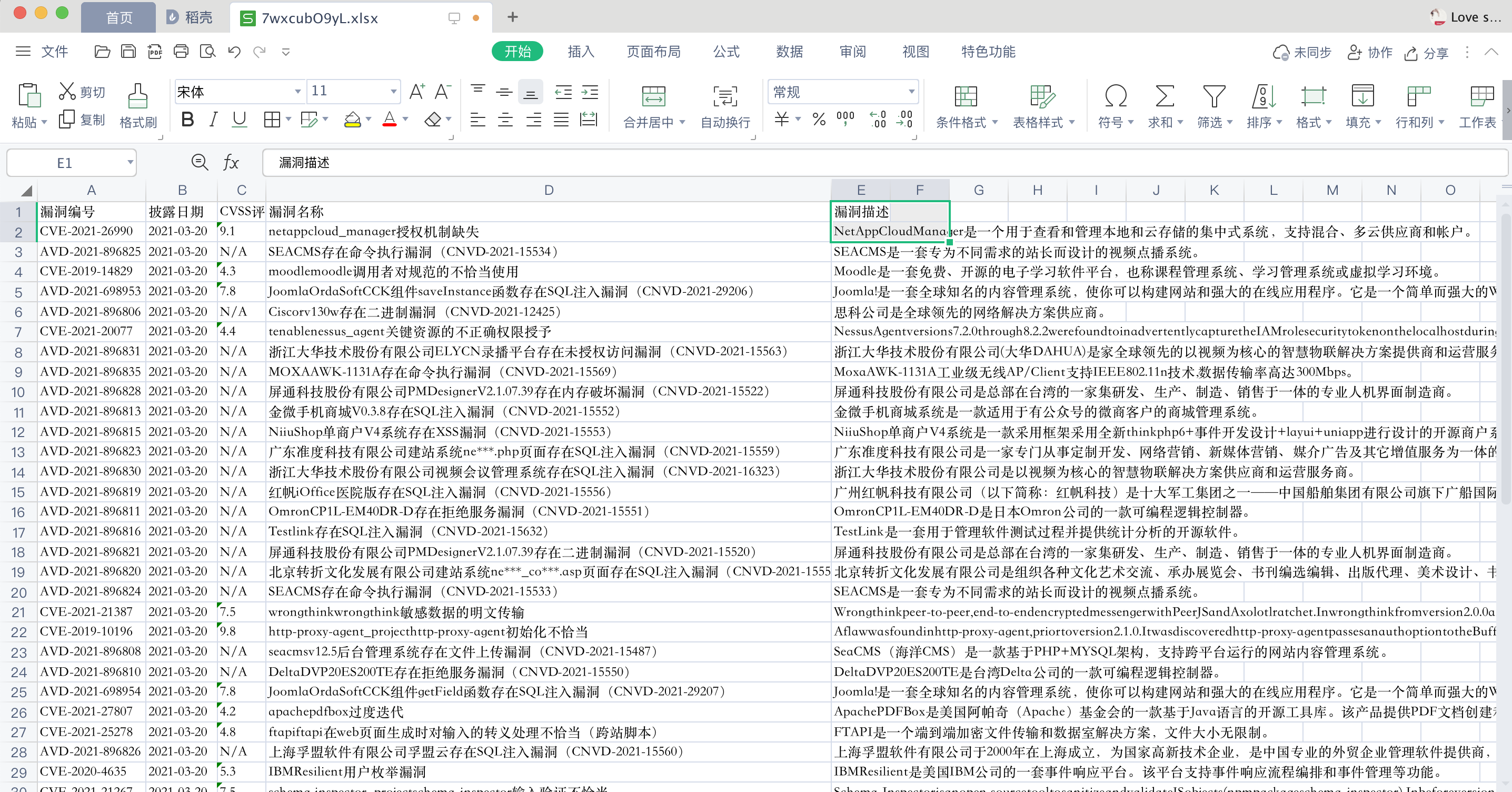
4、数据库示例
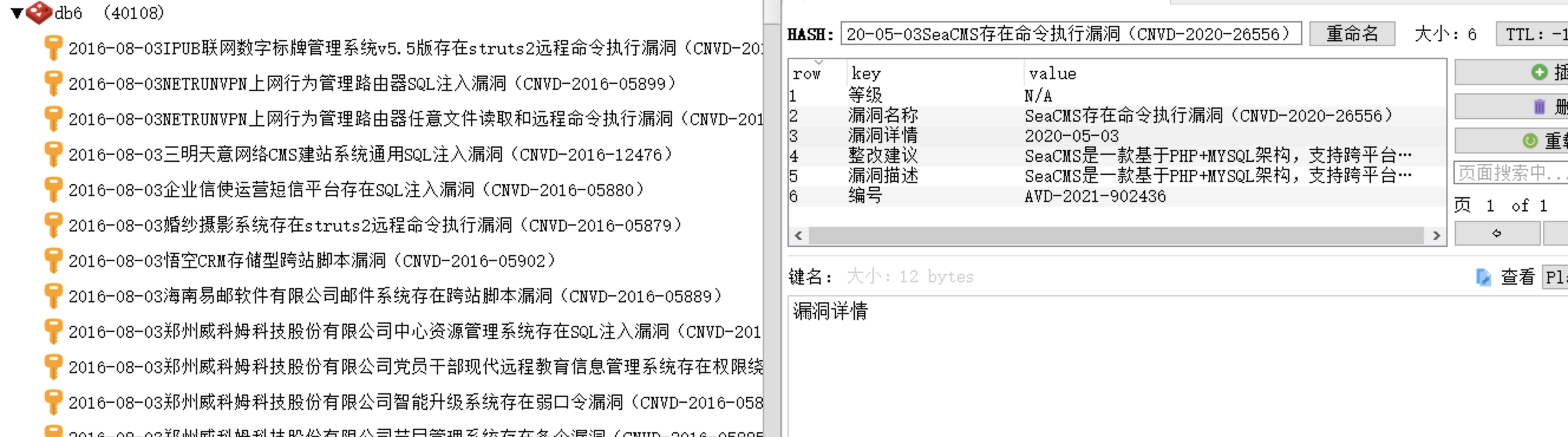
从redis取数据用户查询的数据
1、随机取10个字符作为文件名
file_name = './log/' + ''.join(random.sample(string.ascii_letters + string.digits, 10)) + '.xlsx'
2、redise数据取出来并存入到一个excel文件中
r = redis.Redis(host='127.0.0.1', port=6379,db=6) #连接本地redis数据库的第6个DB
feeds = r.keys("*" + inputdata +"*") #在redis的hash中 匹配用户输入的字符
wb = Workbook() #创建工作簿
ws = wb.active #激活工作表
ws['A1'] = '漏洞编号'
ws['B1'] = '披露日期'
ws['C1'] = 'CVSS评级'
ws['D1'] = '漏洞名称'
ws['E1'] = '漏洞描述'
for key in feeds:
getdata = r.hmget(key,'编号','漏洞详情','等级','漏洞名称','漏洞描述')
ws.append([getdata[0].decode('UTF8'), getdata[1].decode('UTF8'), getdata[2].decode('UTF8'),getdata[3].decode('UTF8'),getdata[4].decode('UTF8')])
wb.save(file_name)
3、文件示例
公众号演示
1、关注回复
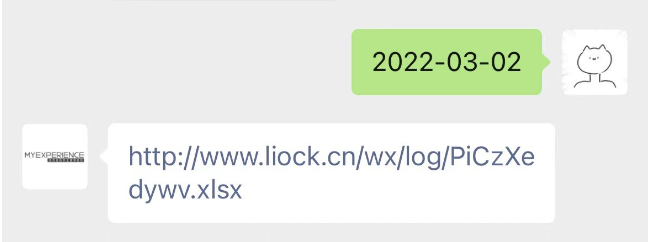
2、按照日期查询当天更新的漏洞

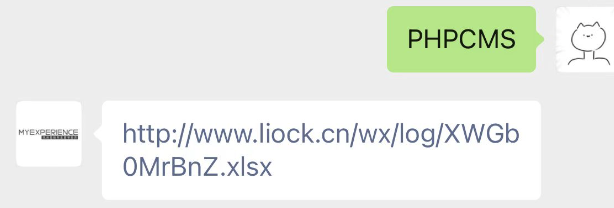
3、按照涉及资产查询历史披露漏洞

代码获取
https://wwz.lanzouv.com/iJ3Ev01zan3i
填坑
1、这个东西呀去年年底就已经在搞了,一个人搞起来慢的很,代码写的像狗屎 也在慢慢规范 快了快了